Prevalence estimation: is it out there?
One of the known unknowns about the NZ coronavirus epidemic is the number of cases we have not detected. There will have been a mixture of people who didn’t get any symptoms, people who are going to show symptoms but haven’t yet, people who got moderately sick but didn’t get tested, and people whose deaths were attributed to some pre-existing condition without testing.
For the decision to loosen restrictions, we care mostly about people who are currently infected, who aren’t (currently) sick enough to get testing, and who aren’t known contacts of previous cases. What can we say about this number — the ‘community prevalence’ of undetected coronavirus infection in New Zealand?
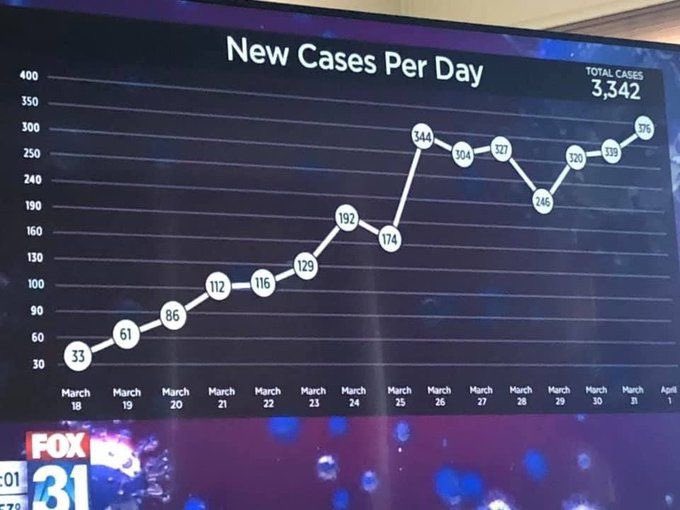
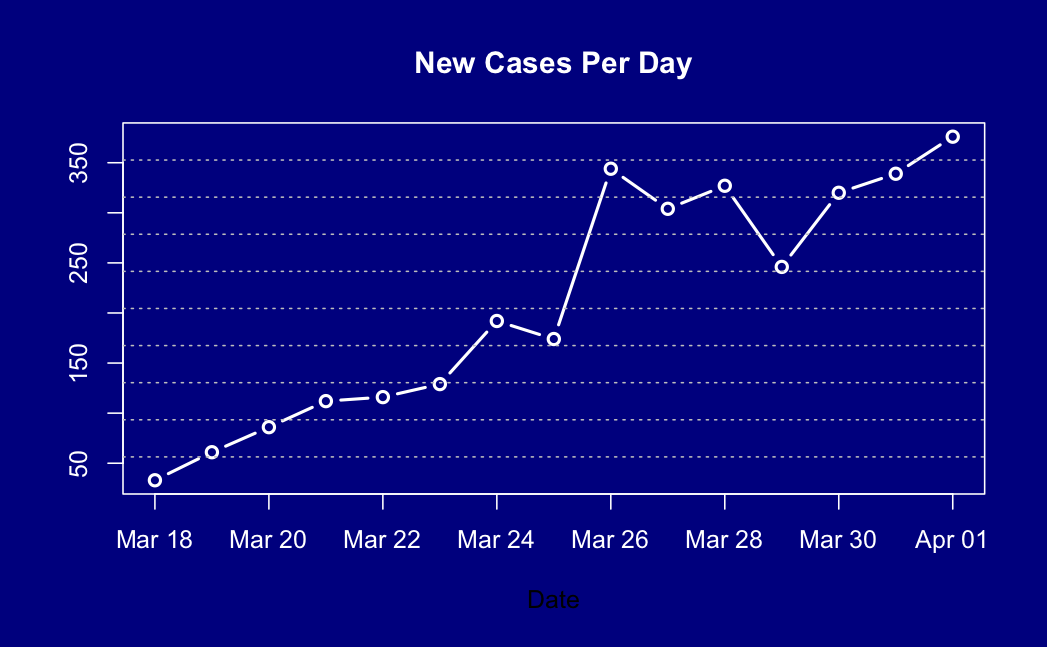
One upper bound is that we’re currently seeing about 1% positive tests in people who either have symptoms or are close contacts of cases. The prevalence in close contacts of cases must be higher than in the general population — this is an infectious disease — so we can be fairly confident the population prevalence is less than 1%.
Are there any other constraints? Well, infection isn’t a static process. If you have coronavirus in 1% of Kiwis, they will pass it on to other people and they themselves will recover. At the moment, under level 4, the epidemic modellers at Te Pūnaha Matatini are estimating a reproduction number of about 0.5, so 50,000 cases will infect half that many new people. Now, if we’re missing nearly all the cases, the modelling might not be all that accurate, but there would have to be tens of thousands of new infections. And at least a few percent of those new cases will be sick enough to need medical treatment. We would quickly notice that many people showing up to hospitals with (by assumption) no known contacts. It isn’t happening. Personally, I have a hard time believing in a prevalence as high as 0.2%, which would mean we’re missing over 80% of cases.
The other constraint would come from testing of healthy people, which is why the government has started doing that. If you wanted an accurate estimate for the population as a whole, you’d need some sort of random population sample, but in the short time it makes more sense to take a sensibly-constructed random sample of supermarkets and then test their customers and employees — if there’s major undetected spread, supermarkets are one of the likely places for it to happen, and they’re also a convenient place to find people who are already leaving home, so you can test them without barging into their bubbles. So, we aren’t getting a true population prevalence estimate, but we are getting an estimate of something a bit like it but probably higher.
How many do we need to test? It depends on how sure you want to be. If we sample 10,000 people and 4 are positive, we could estimate* prevalence at 4/10,000, or 0.04%. But what if no-one is positive? The best estimate clearly isn’t zero!
The question gets more extreme with smaller sample sizes: if we sample 350 people (as was done at the Queenstown PakNSave) and find no cases, what can we say about the prevalence? The classical answer, a valuable trick for hallway statistical consulting, is that if the true rate is 3/N or higher, the chance of seeing no cases in N tests is less than 5%. So, if we see no cases in 350 people, we can be pretty sure the prevalence was less than 3/350, or about 1%. Since we were already pretty sure the prevalence was way less than 1%, that hasn’t got us much further forward. We’re eventually going to want thousands, or tens of thousands, of tests. The Queenstown testing was only a start.
After that introduction, you’ll understand my reaction when Radio NZ’s Checkpoint said there had been a positive test in the Queenstown supermarket, with only two-thirds of the samples run through the lab. Fortunately, it turns out there had been a misunderstanding and there has not yet been a positive result from this community testing. If the true rate is 0.1% there’s a good chance we’ll see a community-positive test soon; if it’s 0.01%, not for a while. And if we’re really at the level of eliminating community transmission, even longer.
Update: Statistical uncertainty in the other direction also matters. If the true prevalence is p and you test N people, you get pN positive tests on average, but your chance of getting no positive tests is e-pN. So, if you test 350 people and the true prevalence is 0.1%, your chance of getting no positive tests is about 70% and your chance of at least one positive is 30%. And a positive test in Queenstown would have been surprising, but shouldn’t have been a complete shock. Two positive tests should be a shock.
* There’s another complication, for another post, in that the test isn’t perfect. The estimate would actually be more like 0.05% or 0.06%.
Recent comments