From the Stuff front page

Now, no-one (maybe even literally no-one) is denying that foreign drivers are at higher risk on average. It’s just that some of us feel exaggerating the problem is unhelpful. The quoted sentence is true only if “the tourist season” is defined, a bit unconventionally, to mean “February”, and probably not even then.
When you click through to the story (from the ChCh Press), the first thing you see is this:
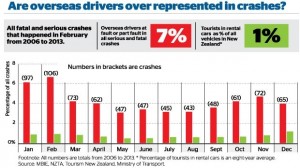
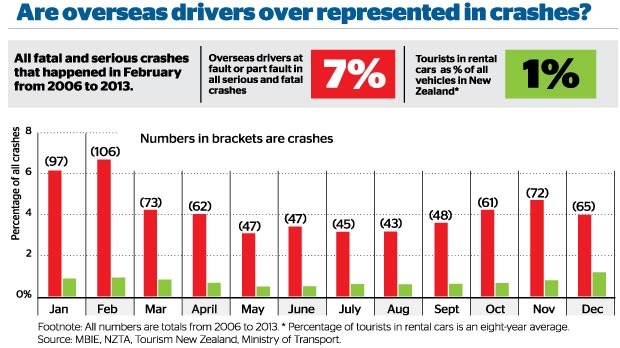
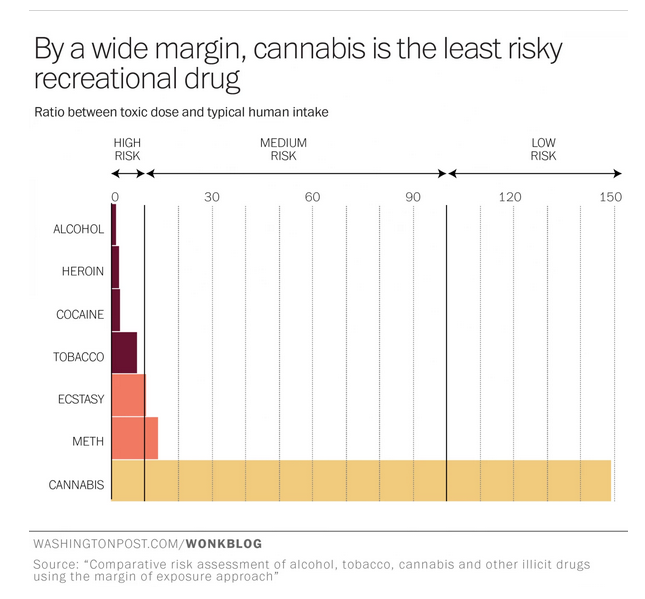
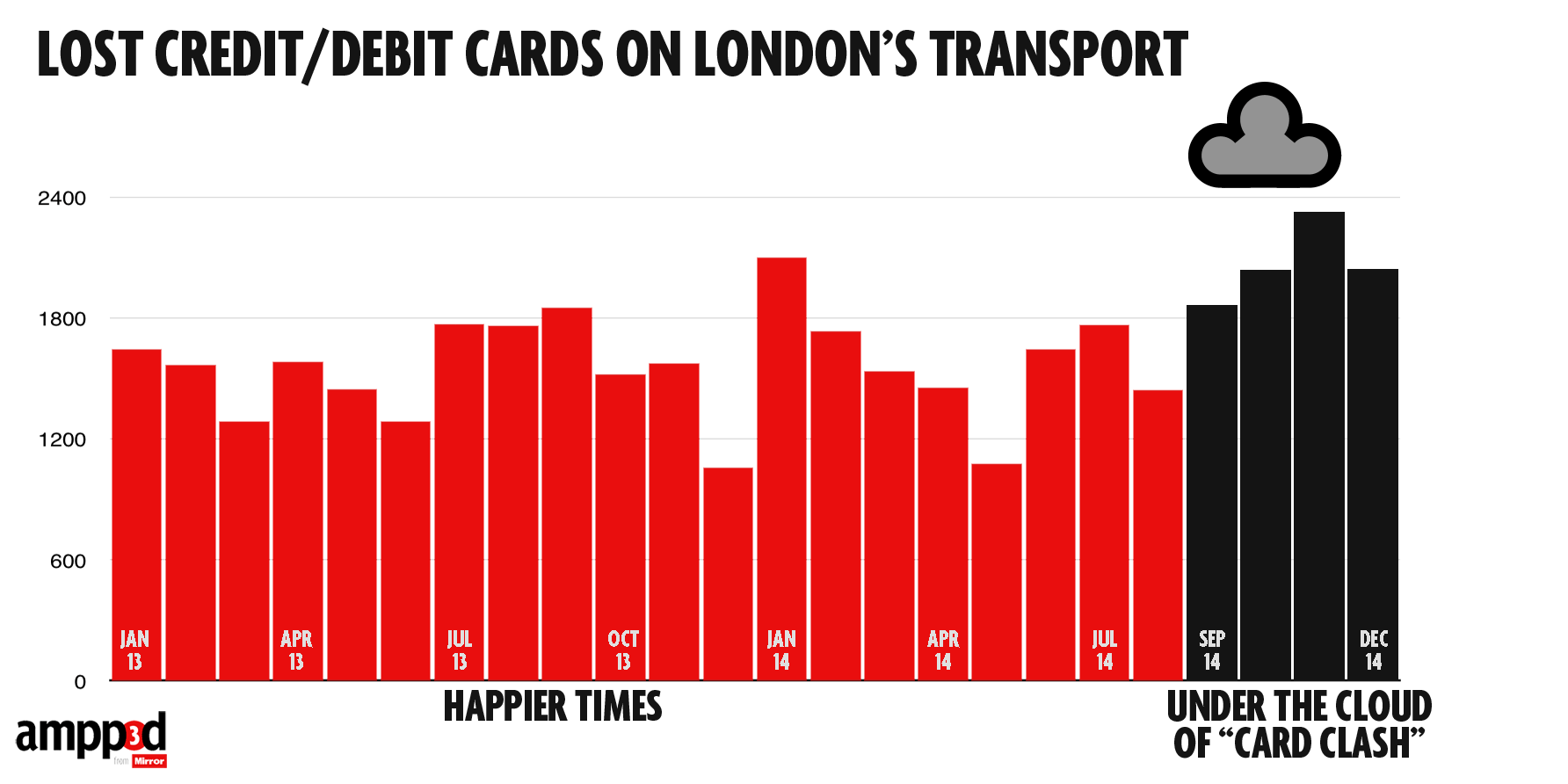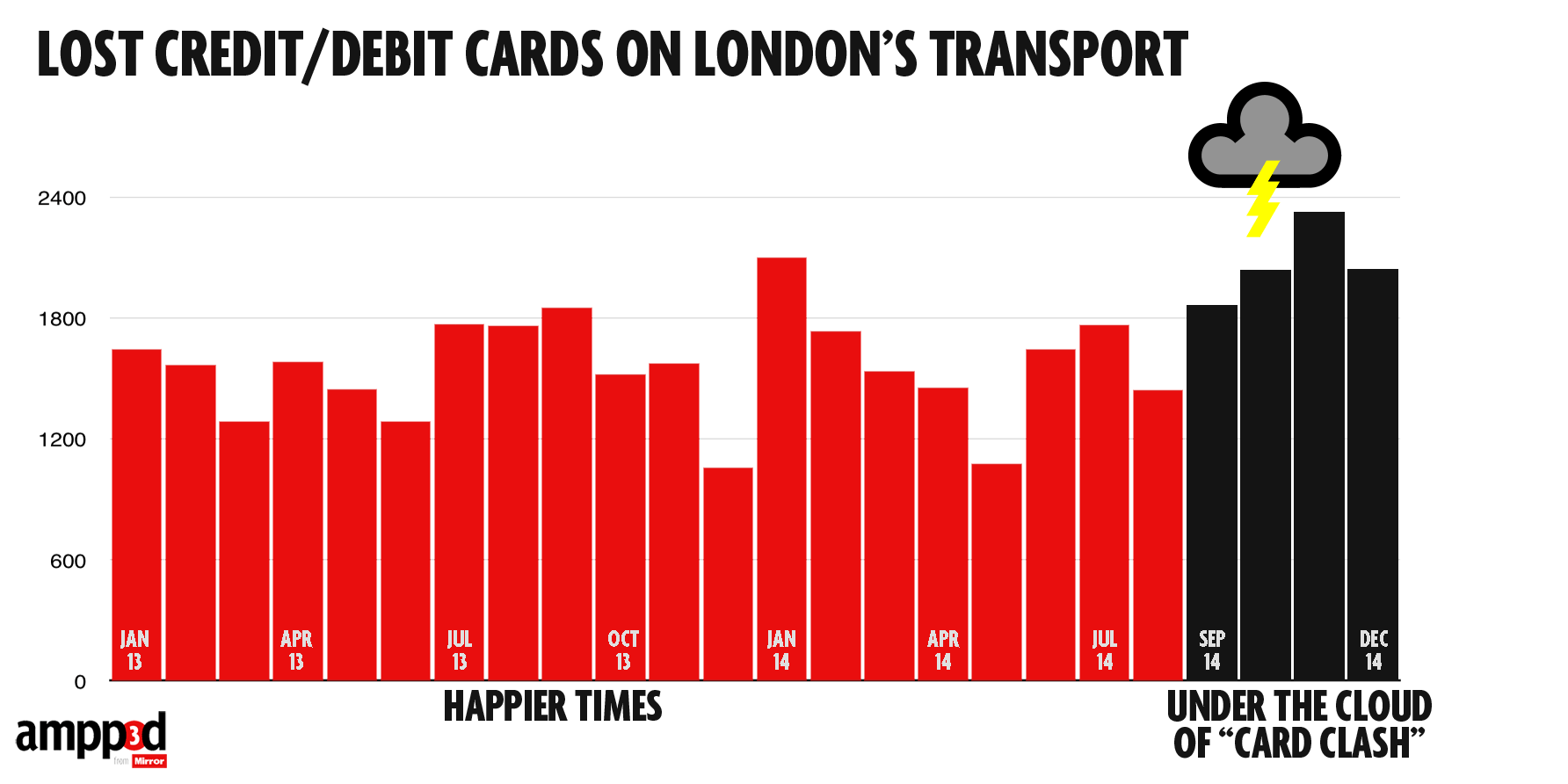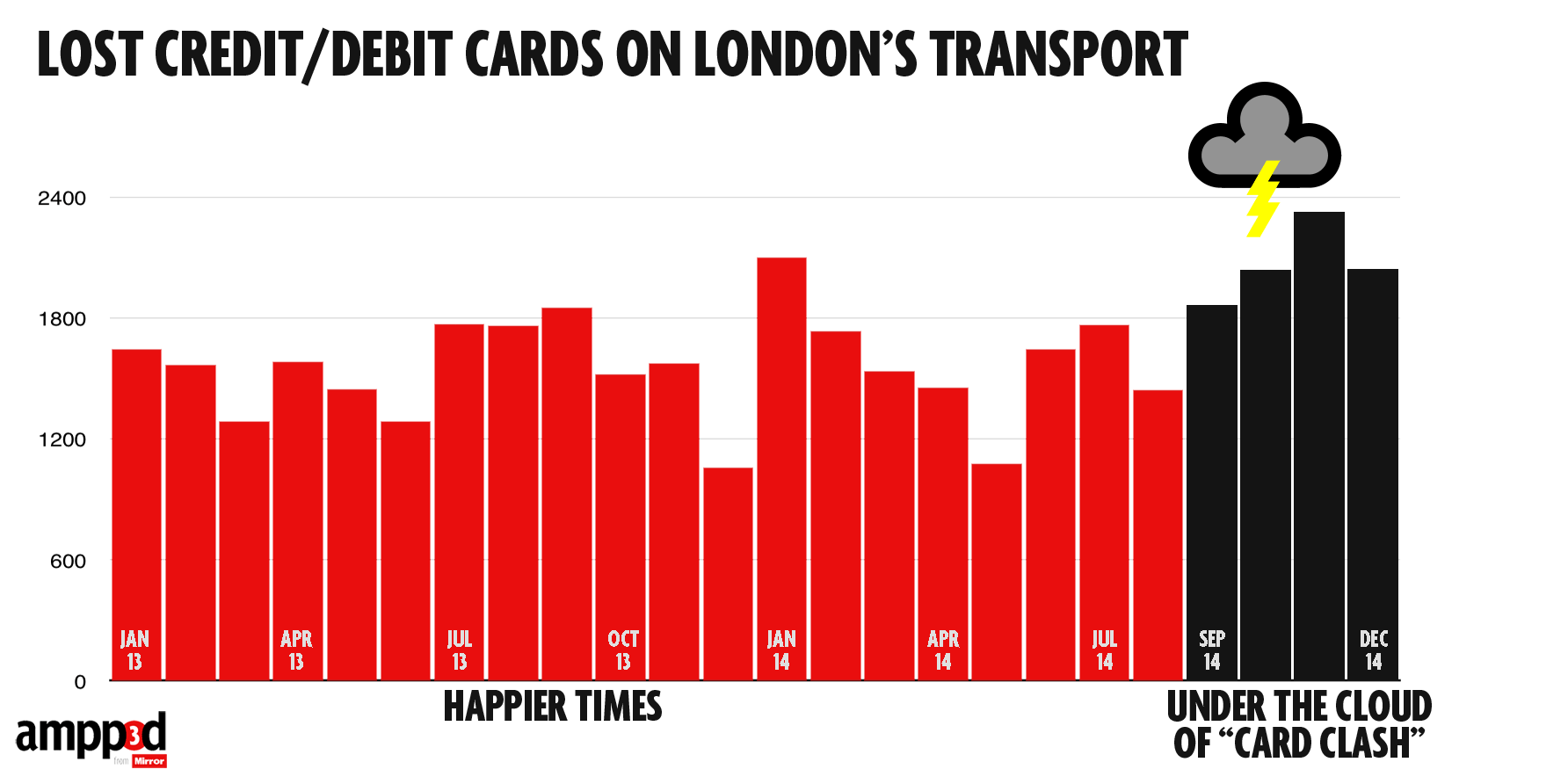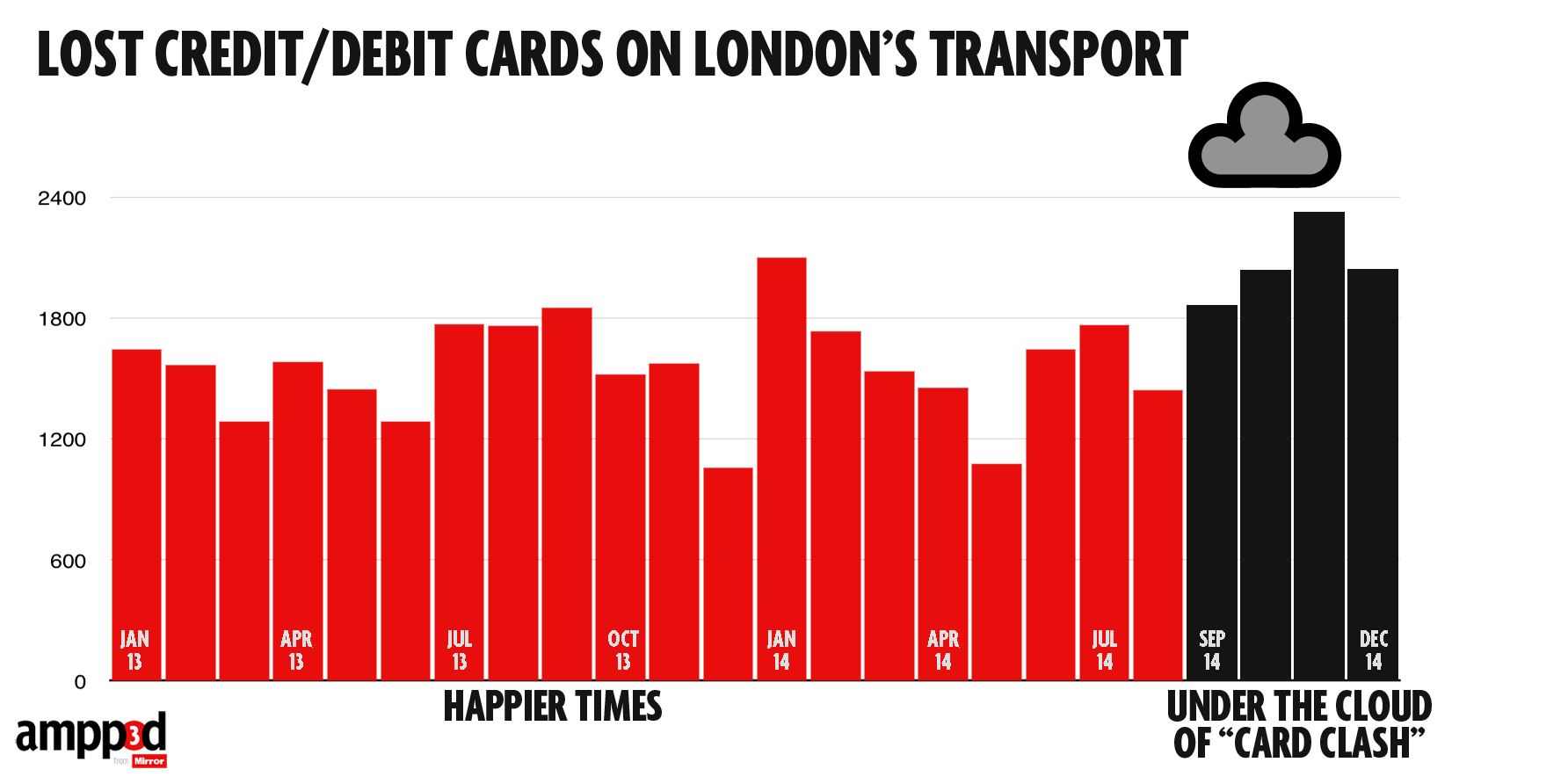
Notice how the graph appears to contradicts itself: the proportion of serious crashes contributed to by a foreign driver ranges from just over 3% in some months to just under 7% at the peak. Obviously, 7% is an overstatement of the actual problem, and if you read sufficiently carefully, the graphs says so. The average is actually 4.3%
The other number headlined here is 1%: cars rented by tourists as a fraction of all vehicles. This is probably an underestimate, as the story itself admits (well, it doesn’t admit the direction of the bias). But the overall bias isn’t what’s most relevant here, if you look at how the calculation is done.
Visitor surveys show that about 1 million people visited Canterbury in 2013.
About 12.6 per cent of all tourists in 2013 drove rental cars, according to government visitor surveys. That means about 126,000 of those 1 million Canterbury visitors drove rental cars. About 10 per cent of international visitors come to New Zealand in January, which means there were about 12,600 tourists in rental cars on Canterbury roads in January.
This was then compared to the 500,000 vehicles on the Canterbury roads in 2013 – figures provided by the Ministry of Transport.
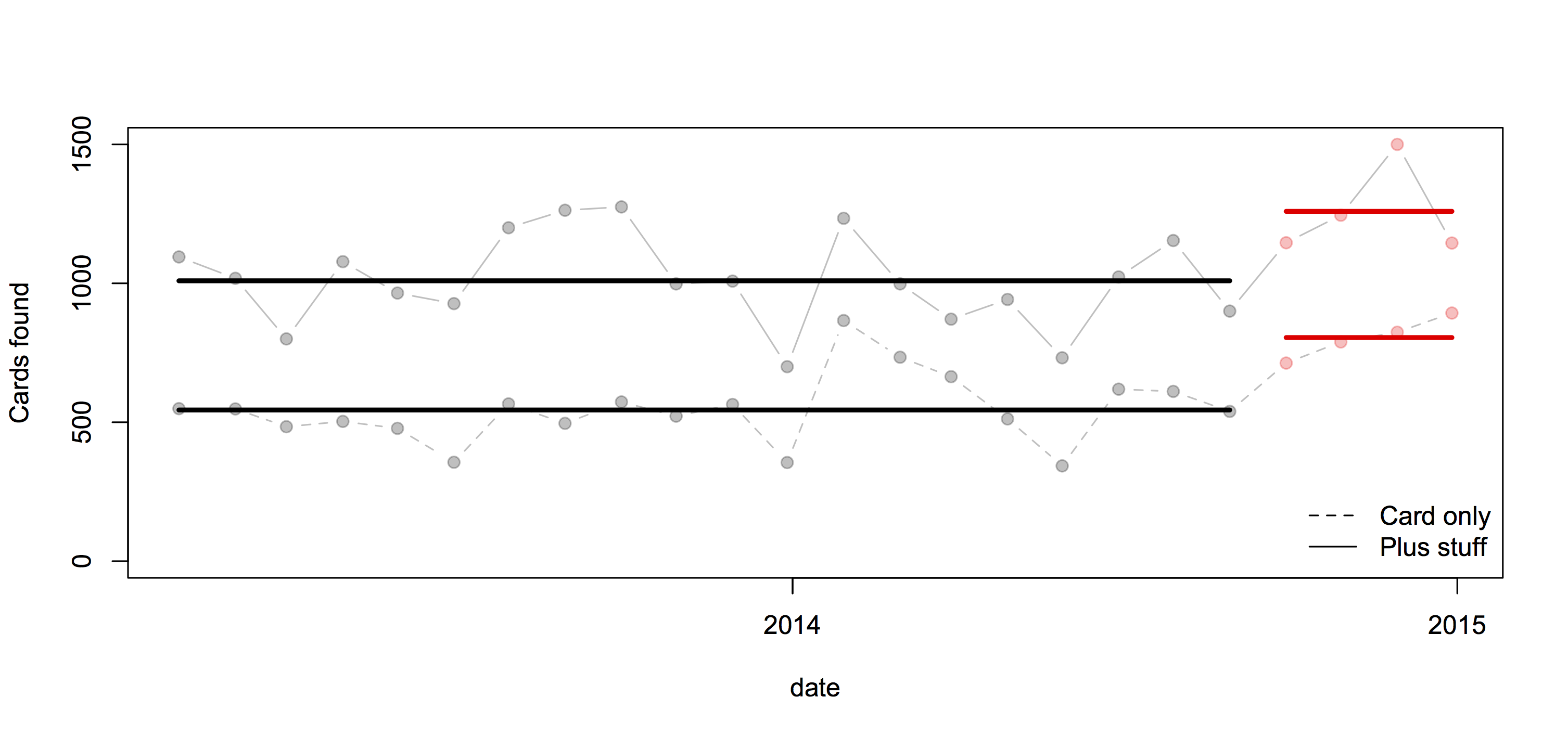
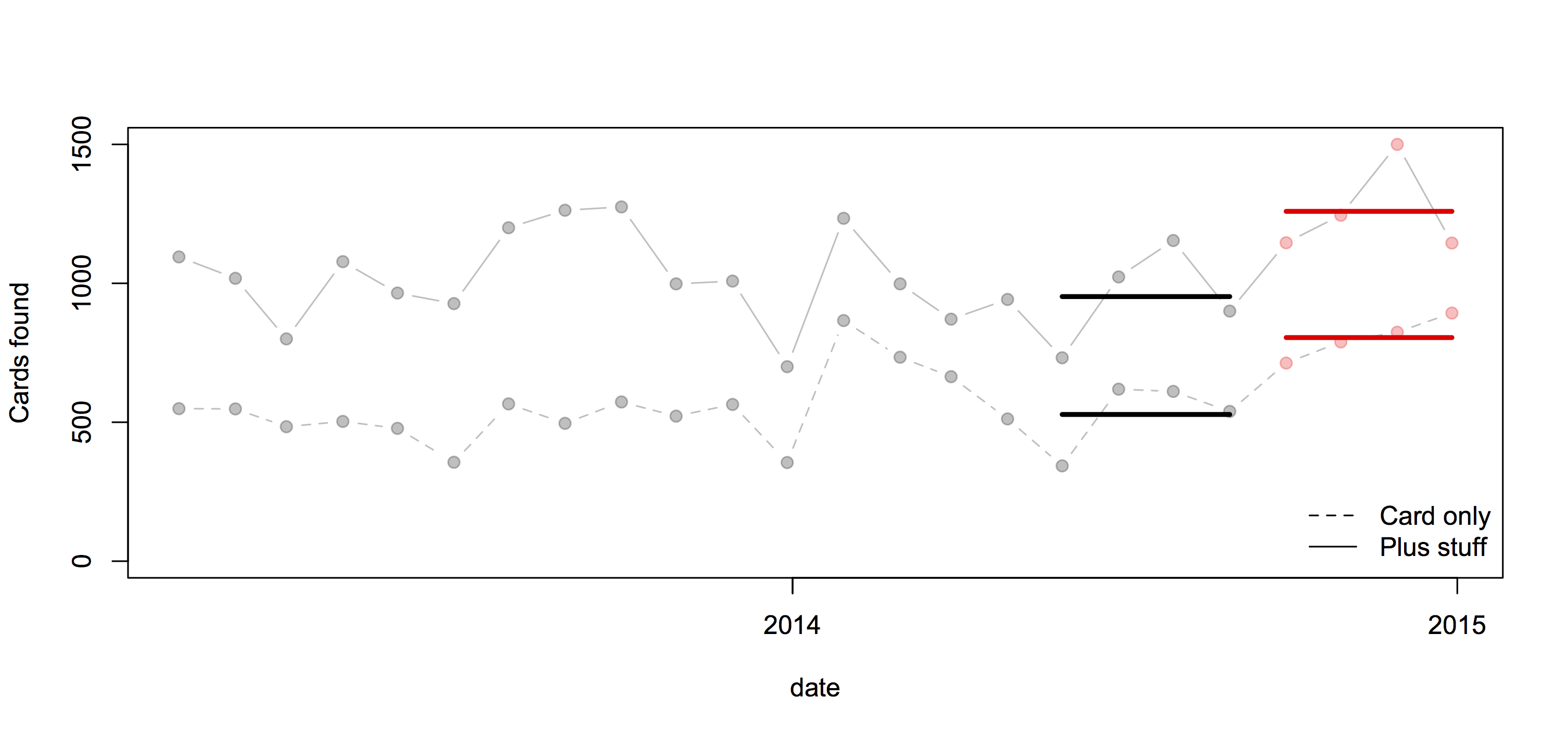
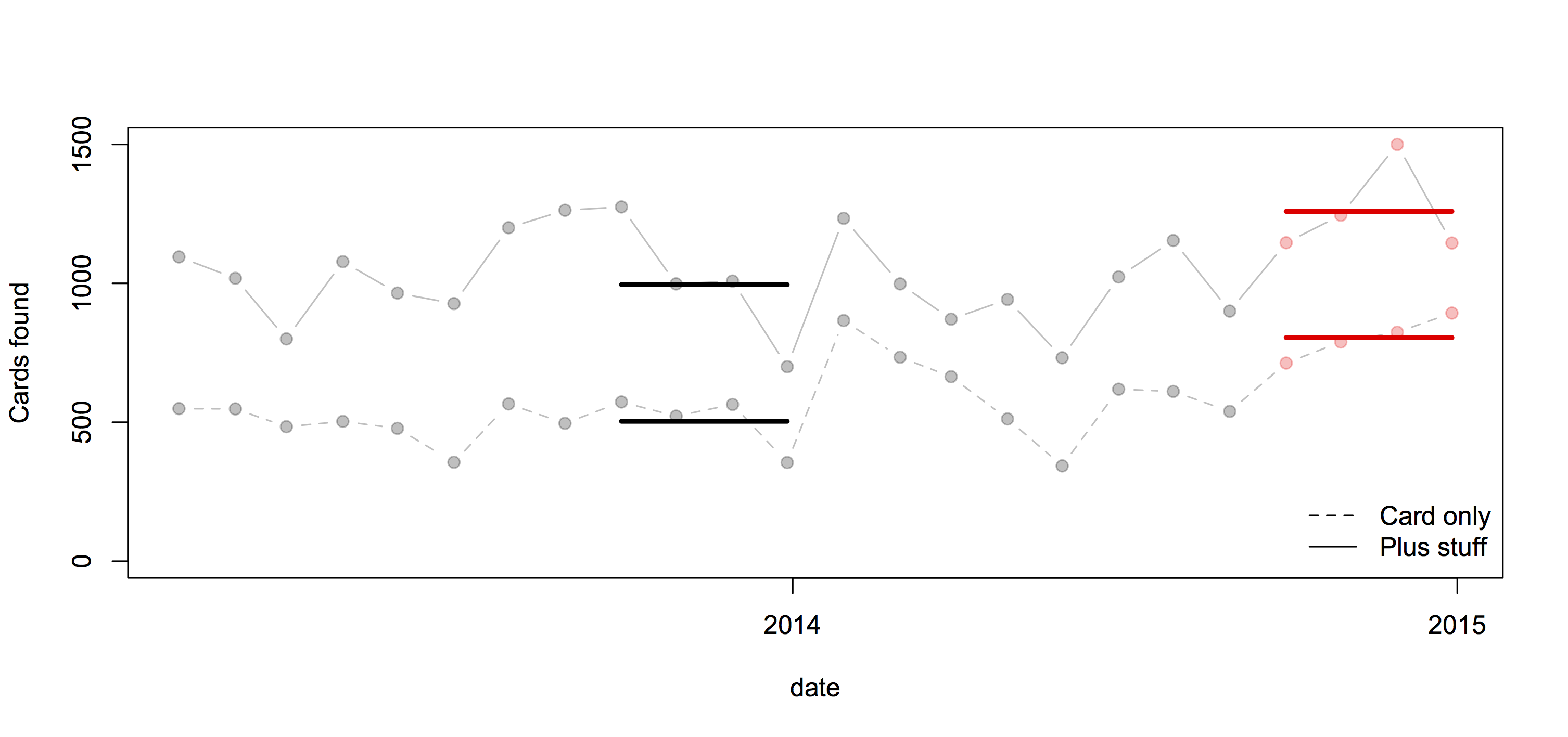
The rental cars aren’t actually counted, they are treated as a constant fraction of visitors. If visitors in summer are more likely to drive long distances, which seems plausible, the denominator will be relatively underestimated in summer and overestimated in winter, giving an exaggerated seasonal variation in risk.
That is, the explanation for more crashes involving foreign drivers in summer could be because summer tourists stay longer or drive more, rather than because summer tourists are intrinsically worse drivers than winter tourists.
All in all, “nine times higher” is a clear overstatement, even if you think crashes in February are somehow more worth preventing than crashes in other months.
Banning all foreign drivers from the roads every February would have prevented 106 fatal or serious injury crashes over the period 2006-2013, just over half a percent of the total. Reducing foreign driver risk by 14% over the whole year would have prevented 109 crashes. Reducing everyone’s risk by 0.6% would have prevented about 107 crashes. Restricting attention to February, like restricting attention to foreign drivers, only makes sense to the extent that it’s easier or less expensive to reduce some people’s risk enormously than to reduce everyone’s risk a tiny amount.
Actually doing something about the problem requires numbers that say what the problem actually is, and strategies, with costs and benefits attached. How many tens of millions of dollars worth of tourists would go elsewhere if they weren’t allowed to drive in New Zealand? Is there a simple, quick test would separate safe from dangerous foreign drivers, that rental companies could administer? How could we show it works? Does the fact that rental companies are willing to discriminate against young drivers but not foreign drivers mean there’s something wrong with anti-discrimination law, or do they just have a better grip on the risks? Could things like rumble strips and median barriers help more for the same cost? How about more police presence?
From 2006 to 2013 NZ averaged about 6 crashes per day causing serious or fatal injury. On average, about one every four days involved a foreign driver. Both these numbers are too high.

{kind=link}