What does 90% accuracy mean?
There was a lot of coverage yesterday about a potential new test for pancreatic cancer. 3News covered it, as did One News (but I don’t have a link). There’s a detailed report in the Guardian, which starts out:
A simple urine test that could help detect early-stage pancreatic cancer, potentially saving hundreds of lives, has been developed by scientists.
Researchers say they have identified three proteins which give an early warning of the disease, with more than 90% accuracy.
This is progress; pancreatic cancer is one of the diseases where there genuinely is a good prospect that early detection could improve treatment. The 90% accuracy, though, doesn’t mean what you probably think it means.
Here’s a graph showing how the error rate of the test changes with the numerical threshold used for diagnosis (figure 4, panel B, from the research paper)
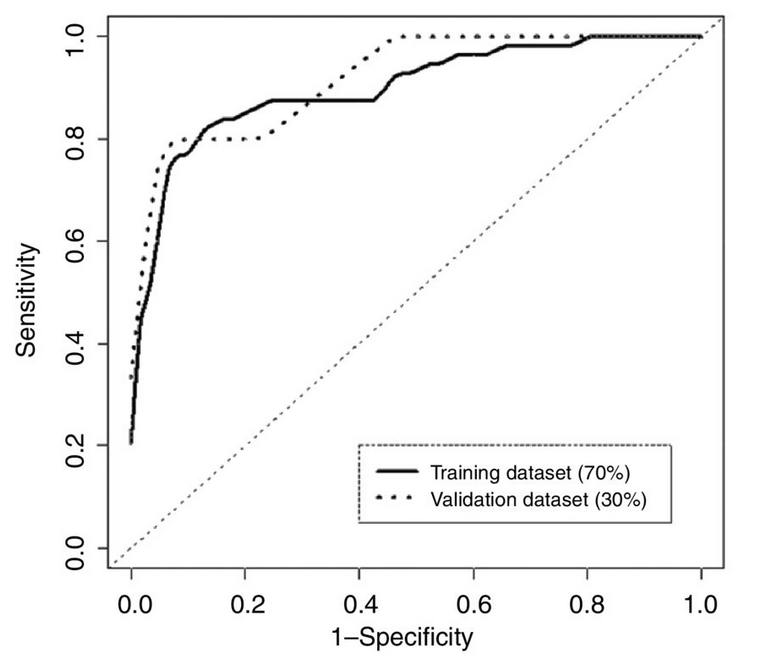
As you move from left to right the threshold decreases; the test is more sensitive (picks up more of the true cases), but less specific (diagnoses more people who really don’t have cancer). The area under this curve is a simple summary of test accuracy, and that’s where the 90% number came from. At what the researchers decided was the optimal threshold, the test correctly reported 82% of early-stage pancreatic cancers, but falsely reported a positive result in 11% of healthy subjects. These figures are from the set of people whose data was used in putting the test together; in a new set of people (“validation dataset”) the error rate was very slightly worse.
The research was done with an approximately equal number of healthy people and people with early-stage pancreatic cancer. They did it that way because that gives the most information about the test for given number of people. It’s reasonable to hope that the area under the curve, and the sensitivity and specificity of the test will be the same in the general population. Even so, the accuracy (in the non-technical meaning of the word) won’t be.
When you give this test to people in the general population, nearly all of them will not have pancreatic cancer. I don’t have NZ data, but in the UK the current annual rate of new cases goes from 4 people out of 100,000 at age 40 to 100 out of 100,000 people 85+. The average over all ages is 13 cases per 100,000 people per year.
If 100,000 people are given the test and 13 have early-stage pancreatic cancer, about 10 or 11 of the 13 cases will have positive tests, but so will 11,000 healthy people. Of those who test positive, 99.9% will not have pancreatic cancer. This might still be useful, but it’s not what most people would think of as 90% accuracy.