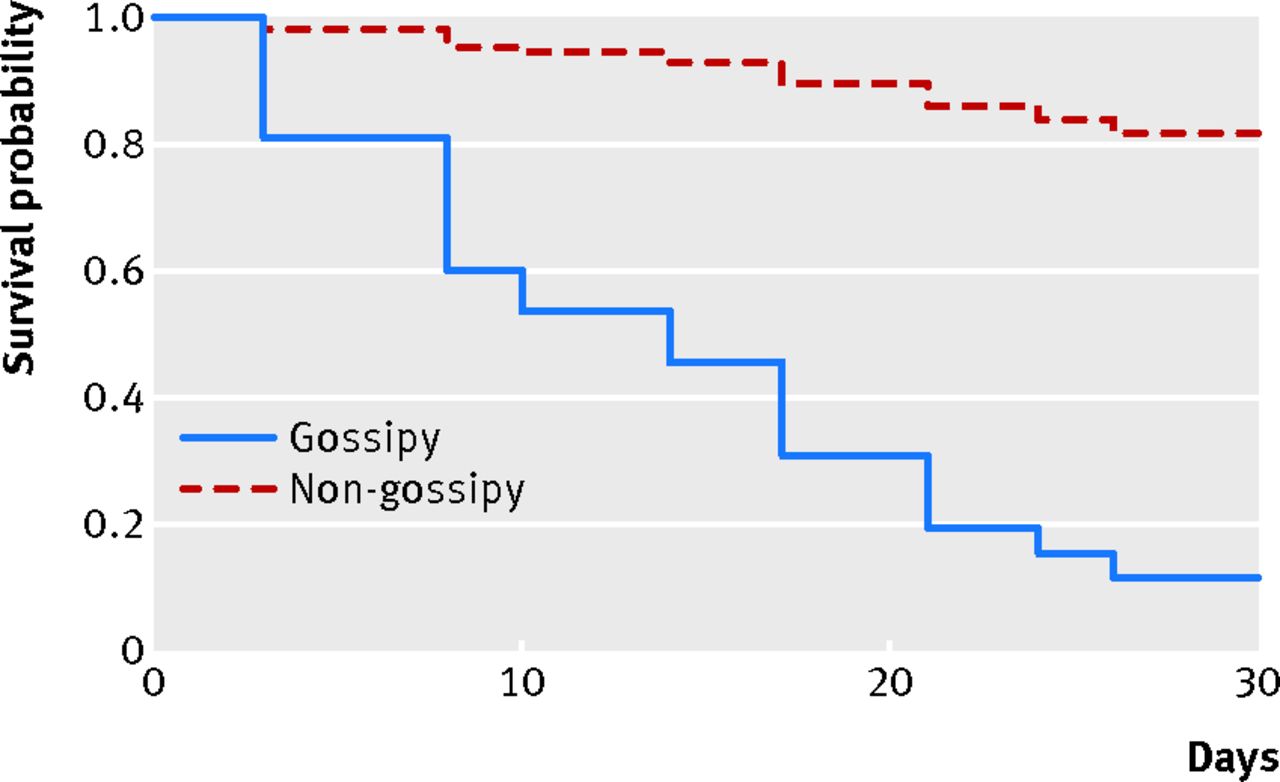
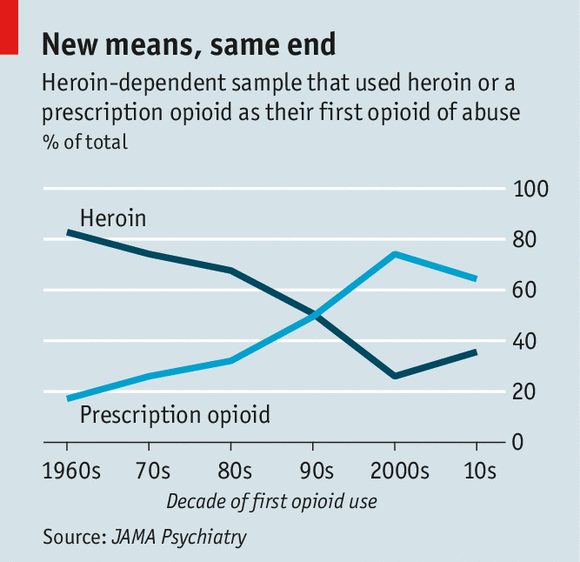
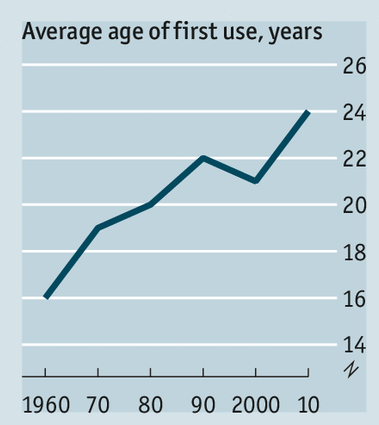
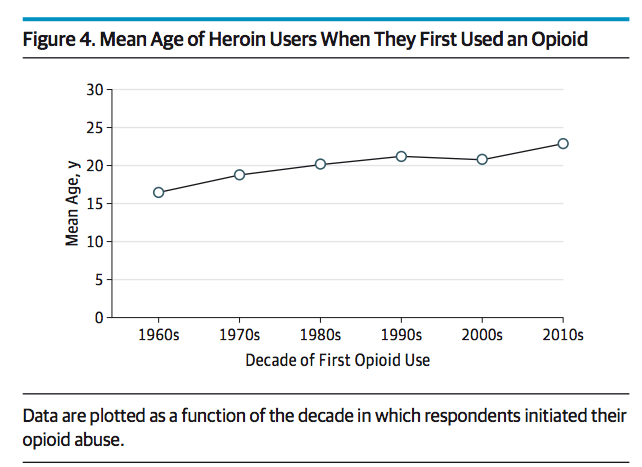
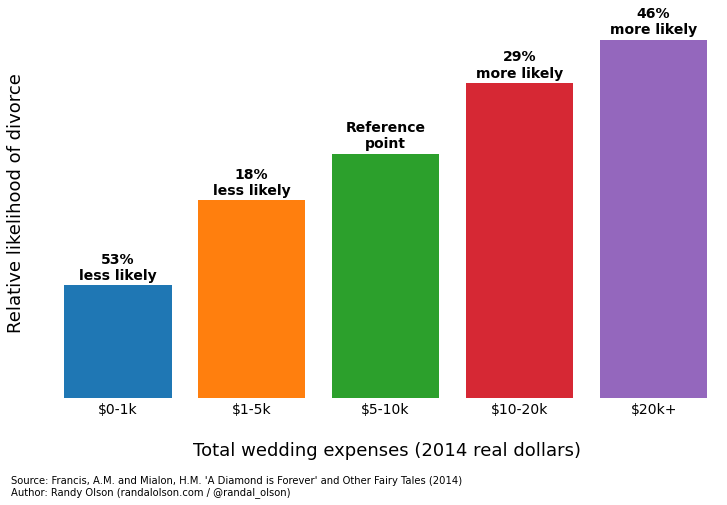
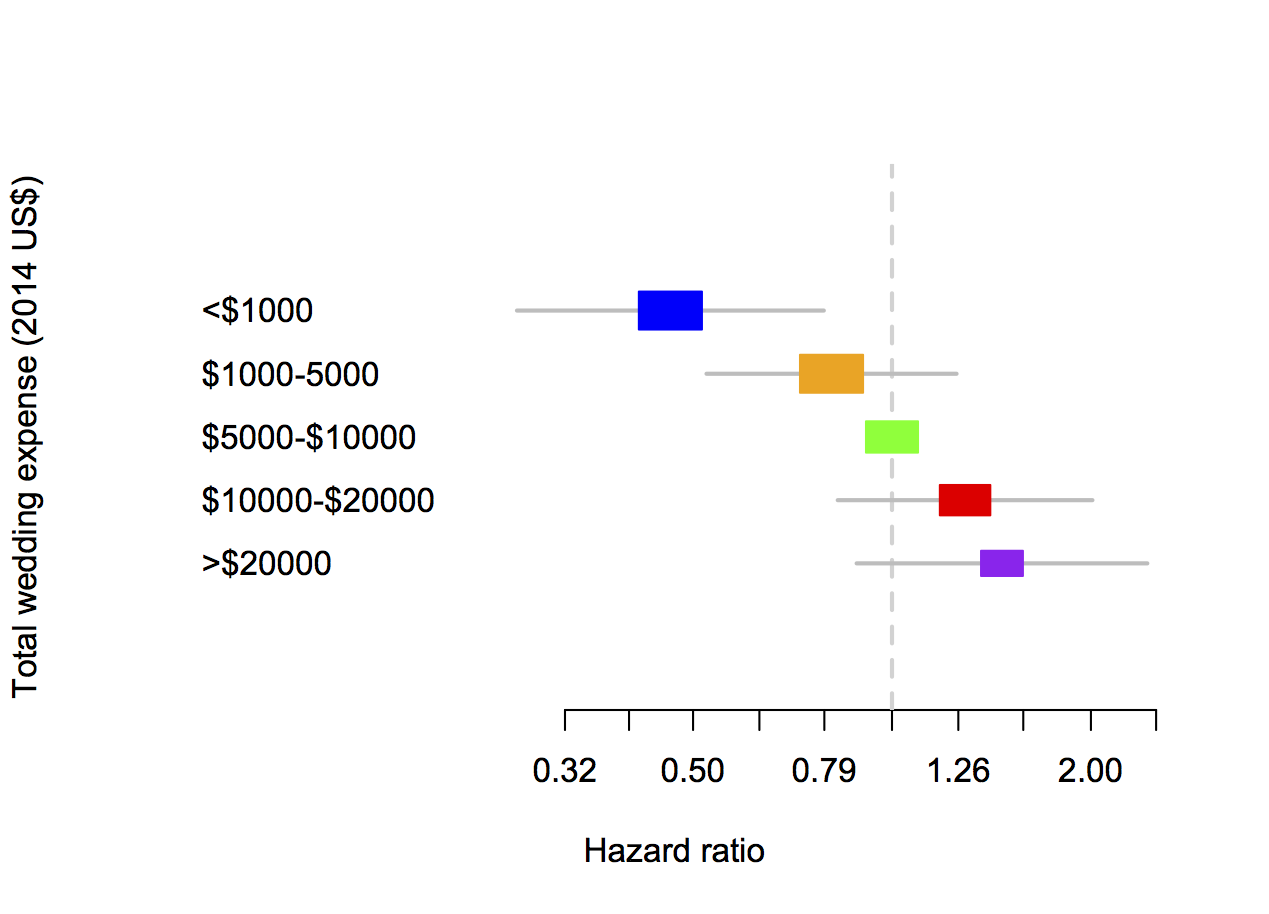
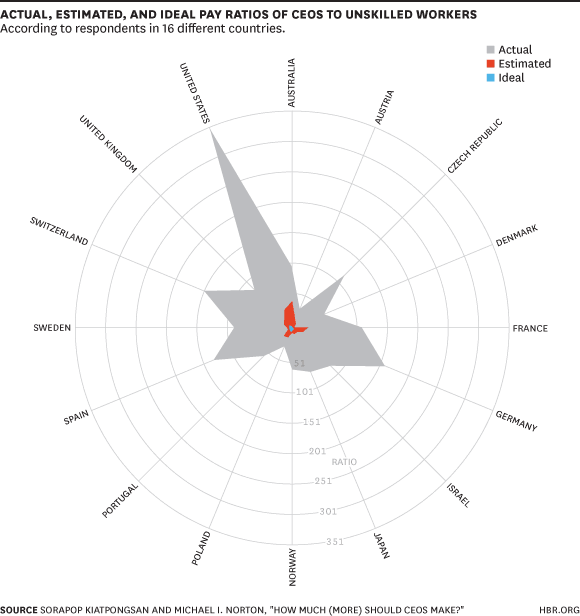
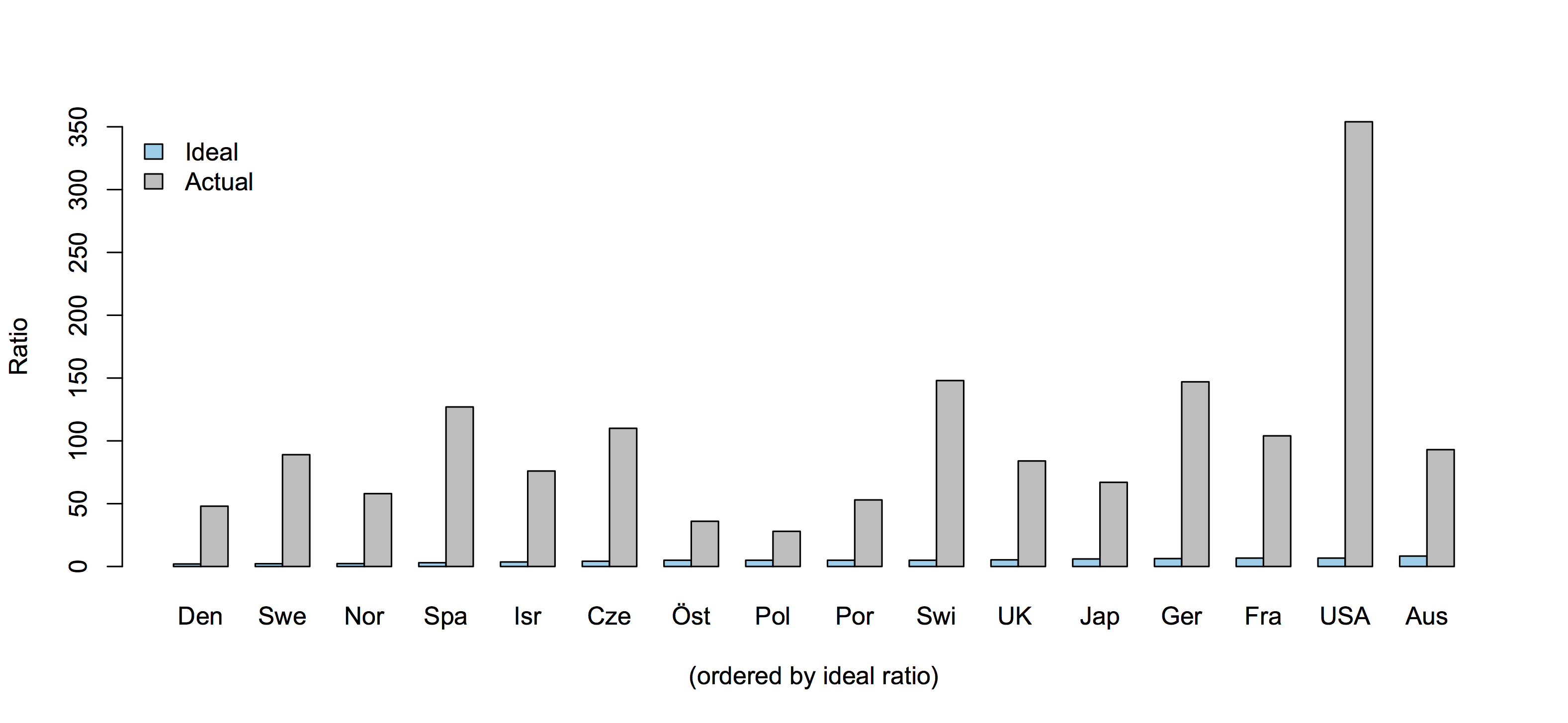
How headlines sometimes matter
From the New Yorker, an unusual source for StatsChat, an article about research on the impact of headlines. I often complain that the headline and lead are much more extreme than the rest of the story, and this research looks into whether this is just naff or actually misleading.
In the case of the factual articles, a misleading headline hurt a reader’s ability to recall the article’s details. That is, the parts that were in line with the headline, such as a declining burglary rate, were easier to remember than the opposing, non-headlined trend. Inferences, however, remained sound: the misdirection was blatant enough that readers were aware of it and proceeded to correct their impressions accordingly. […]
In the case of opinion articles, however, a misleading headline, like the one suggesting that genetically modified foods are dangerous, impaired a reader’s ability to make accurate inferences. For instance, when asked to predict the future public-health costs of genetically modified foods, people who had read the misleading headline predicted a far greater cost than the evidence had warranted.