A bit of background, for non-computer people. Sensible programmers keep their programs in version-control systems. Among other things, these store explanatory messages for each change to the code. In a perfect world, these messages would be concise and informative descriptions of the change. Our world is sadly imperfect.
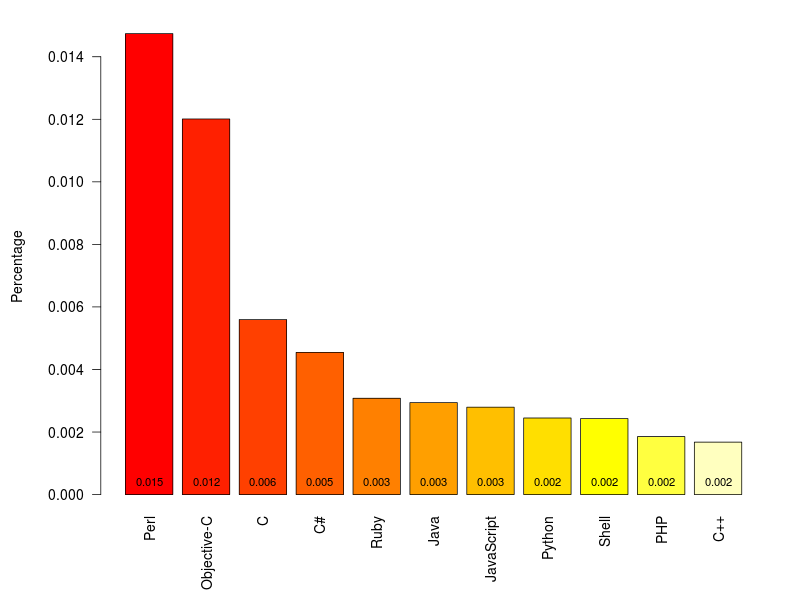
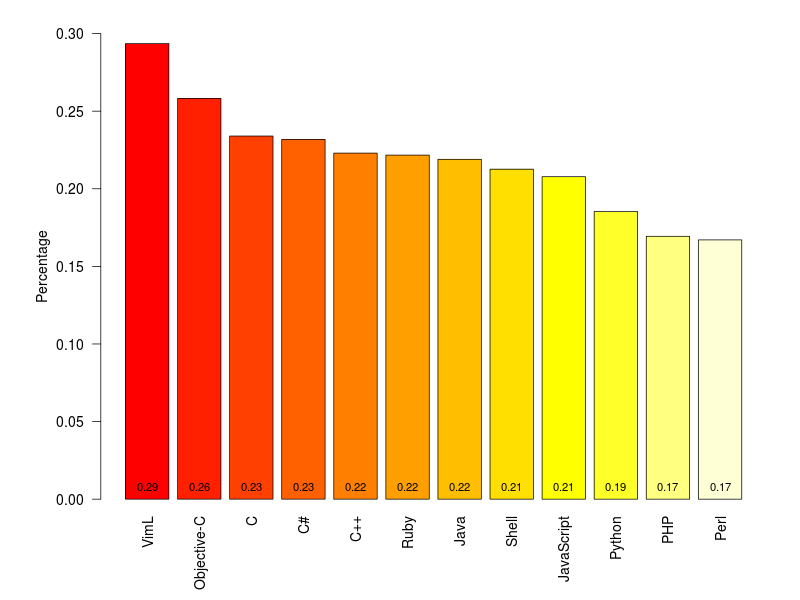
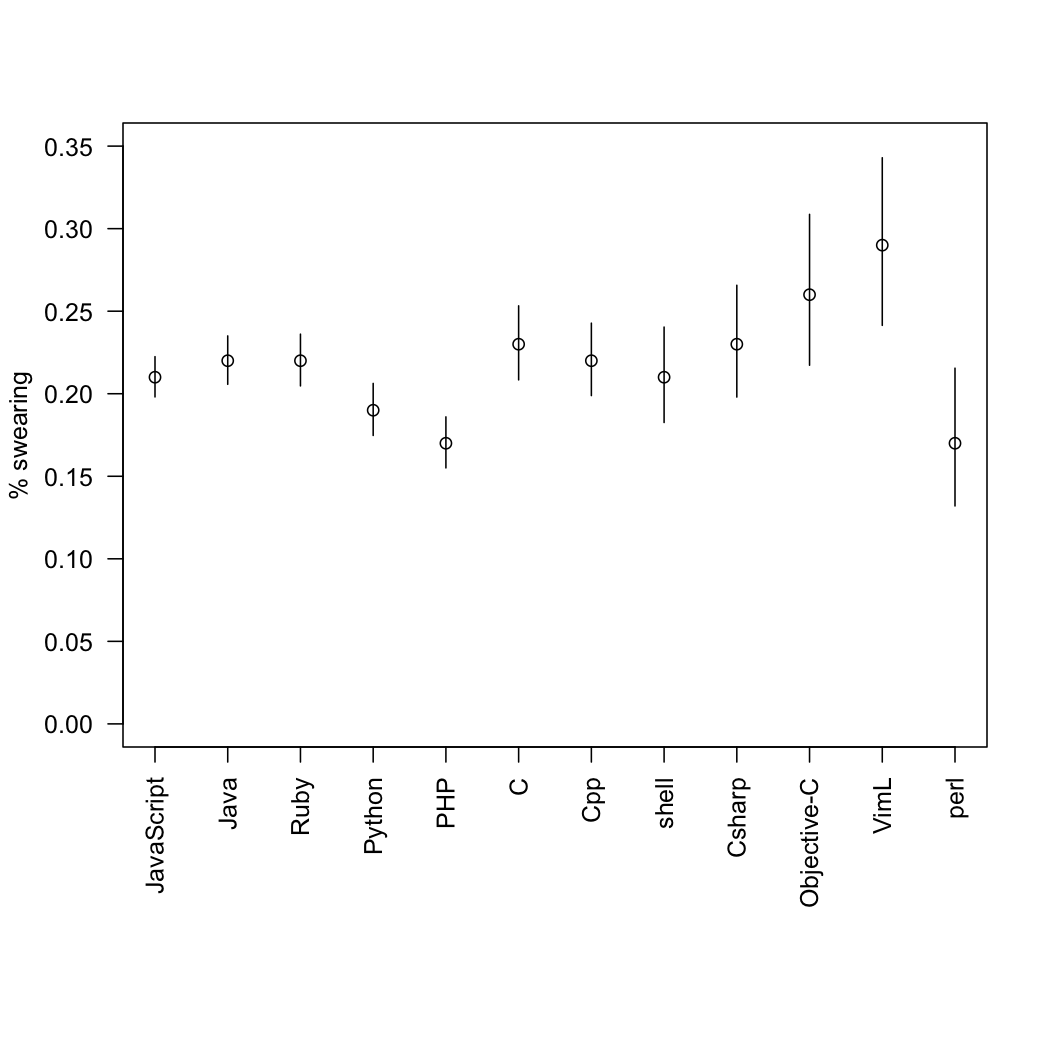
Ramiro Gomez has worked through the archives of change messages on the largest public version-control site, github, to look for “expressions of emotional content”, such as surprise and swearing, and divided these up by the programming language being used. Programmers will not be surprised to learn that Perl has the highest rate of surprise and that the C-like languages have high rates of profanity. If you want to find which words he looked for, you’ll have to read his post.
He notes
Even though a minimum of 40,000 samples per languages seemed adequate to me (I wanted to include Perl), different sample sizes result in varying accuracy, which is a problem and a bit like comparing apples and oranges. Statisticians will probably deny any value of such an approach, still I think it can serve to develop some hypotheses.
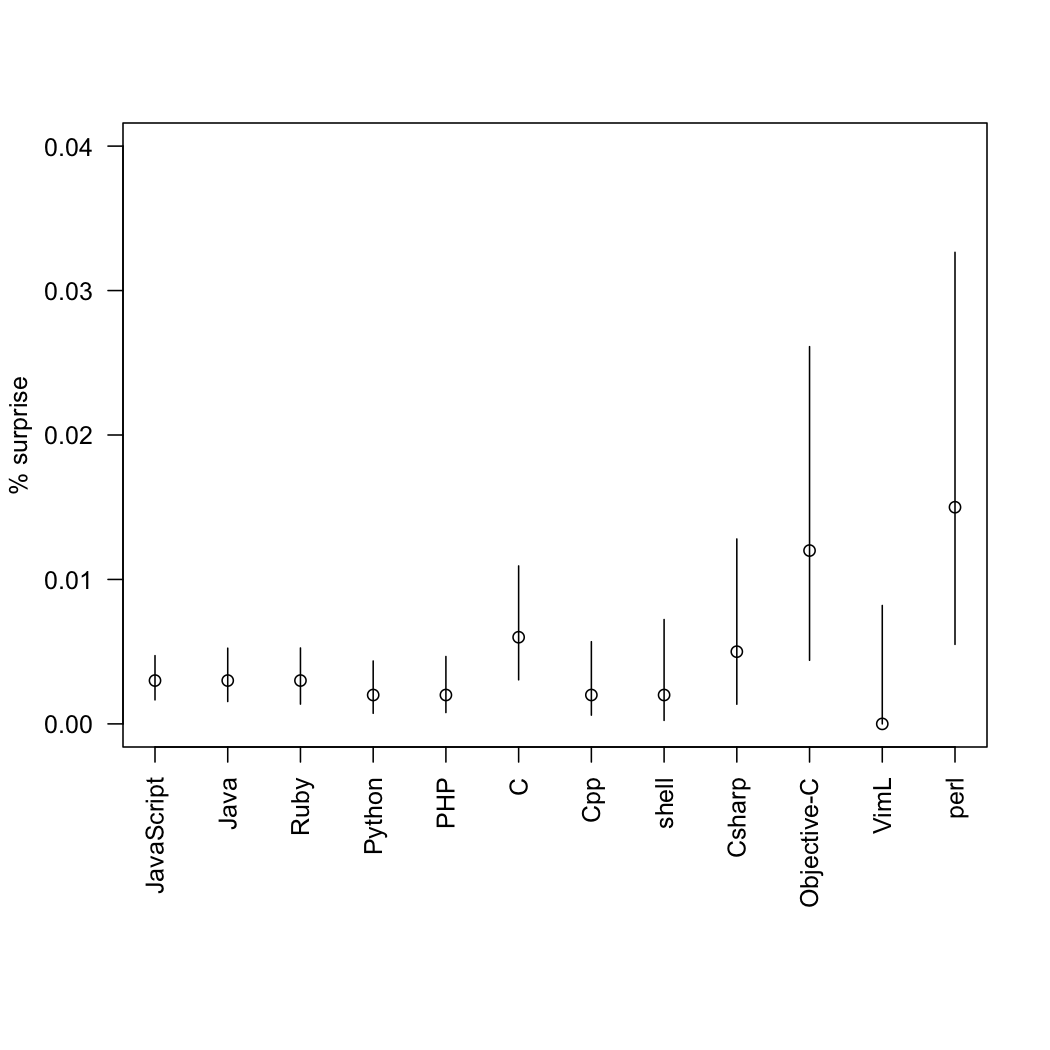
Statisticians have no problem with varying sample sizes, but we would like uncertainty estimates. That’s especially true for the ‘surprise’ category, where the number of messages is very small.
So, as a service to programmers of an inquiring disposition, here are the proportions with confidence intervals. They are slightly approximate, since I had to read the sample sizes off the graph.


(via @TheAtavism and @teh_aimee)