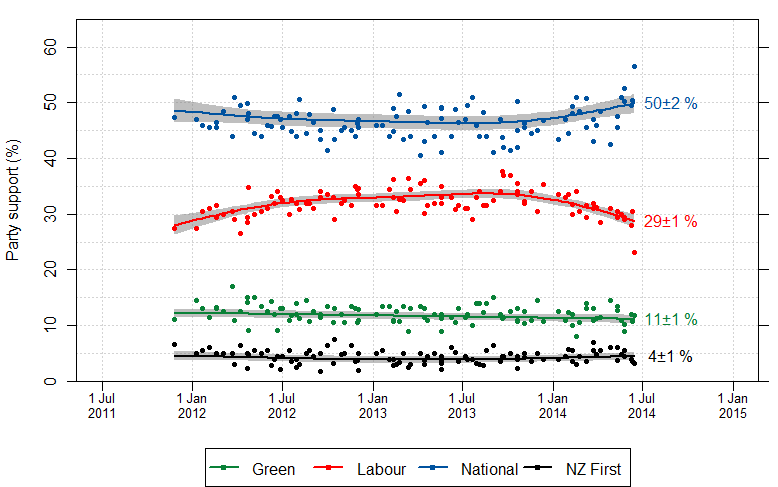
My attention was drawn on Twitter to this post at The Political Scientist arguing that the election poll reporting is misleading because they don’t report the results for the relatively popular “Undecided” party. The post is making a good point, but there are two things I want to comment on. Actually, three things. The zeroth thing is that the post contains the numbers, but only as screenshots, not as anything useful.
The first point is that the post uses correlation coefficients to do everything, and these really aren’t fit for purpose. The value of correlation coefficients is that they summarise the (linear part of the) relationship between two variables in a way that doesn’t involve the units of measurement or the direction of effect (if any). Those are bugs, not features, in this analysis. The question is how the other party preferences have changed with changes in the ‘Undecided’ preference — how many extra respondents picked Labour, say, for each extra respondent who gave a preference. That sort of question is answered (to a straight-line approximation) by regression coefficients, not correlation coefficients.
When I do a set of linear regressions, I estimate that changes in the Undecided vote over the past couple of years have split approximately 70:20:3.5:6.5 between Labour:National:Greens:NZFirst. That confirms the general conclusion in the post: most of the change in Undecided seems to have come from Labour. You can do the regressions the other way around and ask where (net) voters leaving Labour have gone, and find that they overwhelmingly seem to have gone to Undecided.
What can we conclude from this? The conclusion is pretty limited because of the small number of polls (9) and the fact that we don’t actually have data on switching for any individuals. You could fit the data just as well by saying that Labour voters have switched to National and National voters have switched to Undecided by the same amount — this produces the same counts, but has different political implications. Since the trends have basically been a straight line over this period it’s fairly easy to get alternative explanations — if there had been more polls and more up-and-down variation the alternative explanations would be more strained.
The other limitation in conclusions is illustrated by the conclusion of the post
There’s a very clear story in these two correlations: Put simply, as the decided vote goes up so does the reported percentage vote for the Labour Party.
Conversely, as the decided vote goes up, the reported percentage vote for the National party tends to go down.
The closer the election draws the more likely it is that people will make a decision.
But then there’s one more step – getting people to put that decision into action and actually vote.
We simply don’t have data on what happens when the decided vote goes up — it has been going down over this period — so that can’t be the story. Even if we did have data on the decided vote going up, and even if we stipulated that people are more likely to come to a decision near the election, we still wouldn’t have a clear story. If it’s true that people tend to come to a decision near the election, this means the reason for changes in the undecided vote will be different near an election than far from an election. If the reasons for the changes are different, we can’t have much faith that the relationships between the changes will stay the same.
The data provide weak evidence that Labour has lost support to ‘Undecided’ rather than to National over the past couple of years, which should be encouraging to them. In the current form, the data don’t really provide any evidence for extrapolation to the election.
[here’s the re-typed count of preferences data, rounded to the nearest integer]