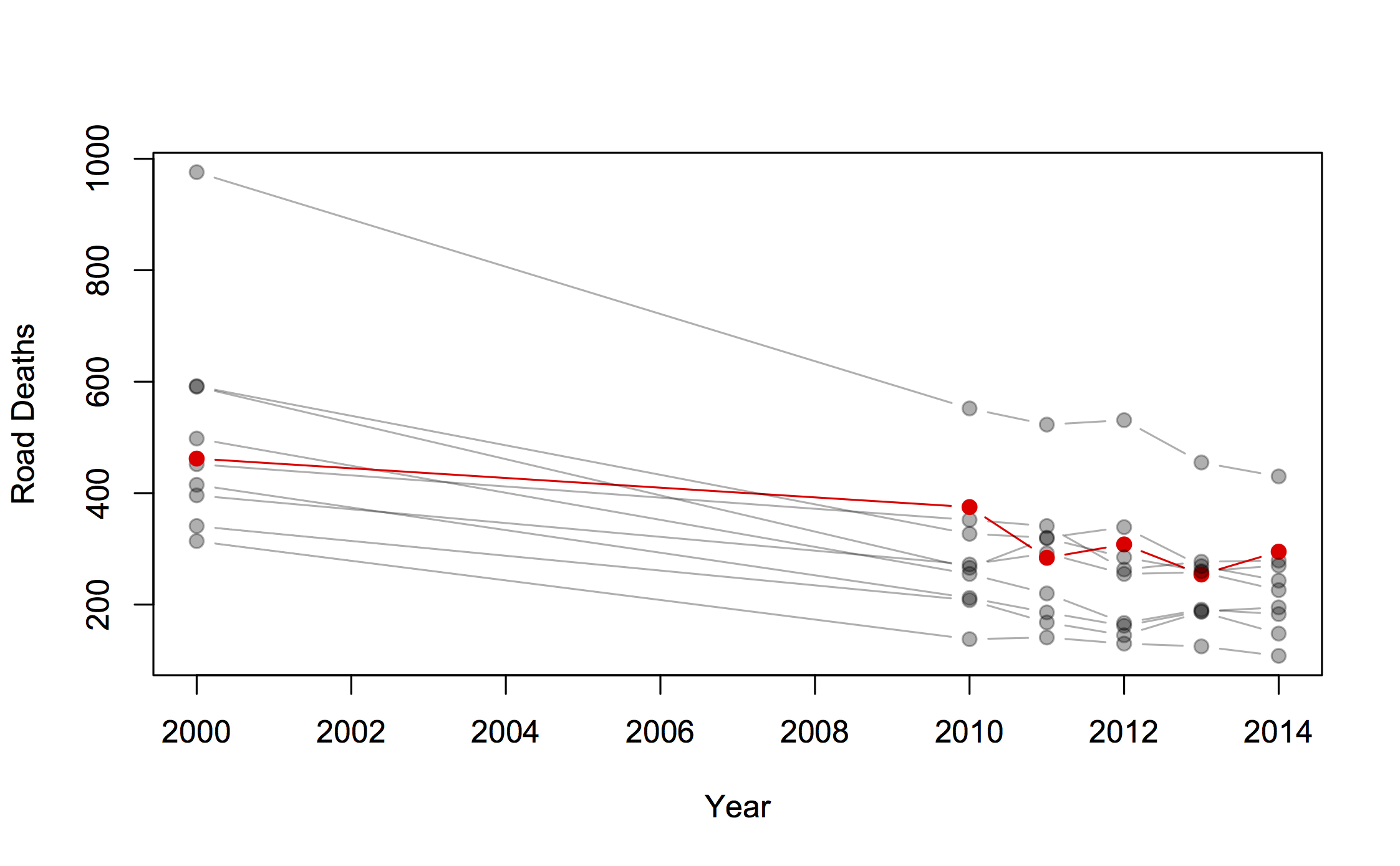
The Herald was, unsurprisingly, unable to resist the temptation of leaked data on house purchases in Auckland. The basic points are:
- Data on the names of buyers for one agency, representing 45% fo the market, for three months
- Based on the names, an estimate that nearly 40% of the buyers were of Chinese ethnicity
- This is more than the proportion of people of Chinese ethnicity in Auckland
- Oh Noes! Foreign speculators! (or Oh Noes! Foreign investors!)
So, how much of this is supported by the various data?
First, the surnames. This should be accurate for overall proportions of Chinese vs non-Chinese ethnicity if it was done carefully. The vast majority of people called, say, “Smith” will not be Chinese; the vast majority of people called, say, “Xu” will be Chinese; people called “Lee” will split in some fairly predictable proportion. The same is probably true for, say, South Asian names, but Māori vs non-Māori would be less reliable.
So, we have fairly good evidence that people of Chinese ancestry are over-represented as buyers from this particular agency, compared to the Auckland population.
Second: the representativeness of the agency. It would not be at all surprising if migrants, especially those whose first language isn’t English, used real estate agents more than people born in NZ. It also wouldn’t be surprising if they were more likely to use some agencies than others. However, the claim is that these data represent 45% of home sales. If that’s true, people with Chinese names are over-represented compared to the Auckland population no matter how unrepresentative this agency is. Even if every Chinese buyer used this agency, the proportion among all buyers would still be more than 20%.
So, there is fairly good evidence that people of Chinese ethnicity are buying houses in Auckland at a higher rate than their proportion of the population.
The Labour claim extends this by saying that many of the buyers must be foreign. The data say nothing one way or the other about this, and it’s not obvious that it’s true. More precisely, since the existence of foreign investors is not really in doubt, it’s not obvious how far it’s true. The simple numbers don’t imply much, because relatively few people are housing buyers: for example, house buyers named “Wang” in the data set are less than 4% of Auckland residents named “Wang.” There are at least three other competing explanations, and probably more.
First, recent migrants are more likely to buy houses. I bought a house three years ago. I hadn’t previously bought one in Auckland. I bought it because I had moved to Auckland and I wanted somewhere to live. Consistent with this explanation, people with Korean and Indian names, while not over-represented to the same extent are also more likely to be buying than selling houses, by about the same ratio as Chinese.
Second, it could be that (some subset of) Chinese New Zealanders prefer real estate as an investment to, say, stocks (to an even greater extent than Aucklanders in general). Third, it could easily be that (some subset of) Chinese New Zealanders have a higher savings rate than other New Zealanders, and so have more money to invest in houses.
Personally, I’d guess that all these explanations are true: that Chinese New Zealanders (on average) buy both homes and investment properties more than other New Zealanders, and that there are foreign property investors of Chinese ethnicity. But that’s a guess: these data don’t tell us — as the Herald explicitly points out.
One of the repeated points I make on StatsChat is that you need to distinguish between what you measured and what you wanted to measure. Using ‘Chinese’ as a surrogate for ‘foreign’ will capture many New Zealanders and miss out on many foreigners.
The misclassifications aren’t just unavoidable bad luck, either. If you have a measure of ‘foreign real estate ownership’ that includes my next-door neighbours and excludes James Cameron, you’re doing it wrong, and in a way that has a long and reprehensible political history.
But on top of that, if there is substantial foreign investment and if it is driving up prices, that’s only because of the artificial restrictions on the supply of Auckland houses. If Auckland could get its consent and zoning right, so that more money meant more homes, foreign investment wouldn’t be a problem for people trying to find somewhere to live. That’s a real problem, and it’s one that lies within the power of governments to solve.