The statistical significance filter
Attention conservation notice: long and nerdy, but does have pictures.
You may have noticed that I often say about newsy research studies that they are are barely statistically significant or they found only weak evidence, but that I don’t say that about large-scale clinical trials. This isn’t (just) personal prejudice. There are two good reasons why any given evidence threshold is more likely to be met in lower-quality research — and while I’ll be talking in terms of p-values here, getting rid of them doesn’t solve this problem (it might solve other problems). I’ll also be talking in terms of an effect being “real” or not, which is again an oversimplification but one that I don’t think affects the point I’m making. Think of a “real” effect as one big enough to write a news story about.
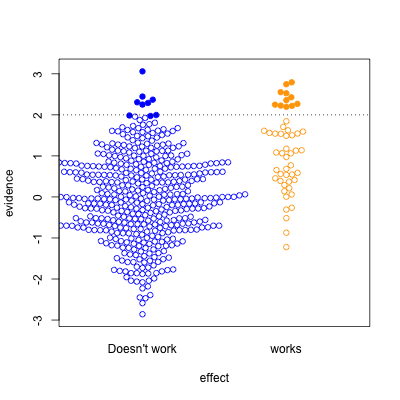
This graph shows possible results in statistical tests, for research where the effect of the thing you’re studying is real (orange) or not real (blue). The solid circles are results that pass your statistical evidence threshold, in the direction you wanted to see — they’re press-releasable as well as publishable.
Only about half the ‘statistically significant’ results are real; the rest are false positives.
I’ve assumed the proportion of “real” effects is about 10%. That makes sense in a lot of medical and psychological research — arguably, it’s too optimistic. I’ve also assumed the sample size is too small to reliably pick up plausible differences between blue and yellow — sadly, this is also realistic.
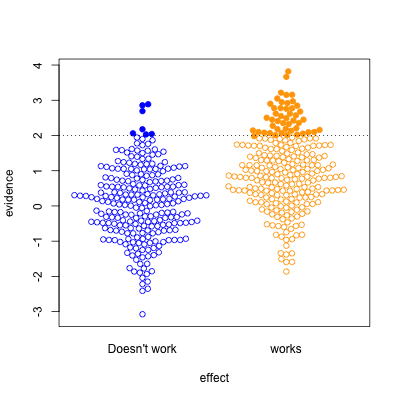
In the second graph, we’re looking at a setting where half the effects are real and half aren’t. Now, of the effects that pass the threshold, most are real. On the other hand, there’s a lot of real effects that get missed. This was the setting for a lot of clinical trials in the old days, when they were done in single hospitals or small groups.
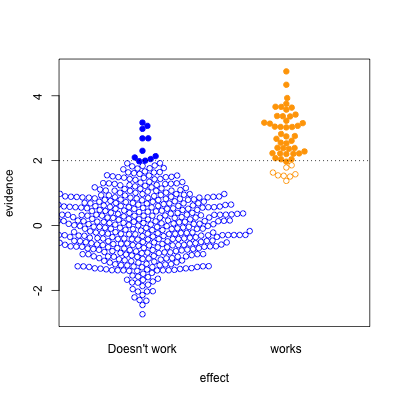
The third case is relatively implausible hypotheses — 10% true — but well-designed studies. There are still the same number of false positives, but many more true positives. A better-designed study means that positive results are more likely to be correct.
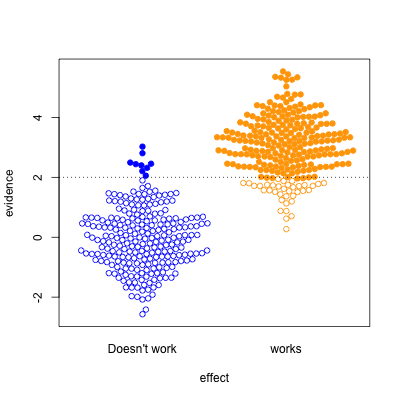
Finally, the setting of well-conducted clinical trials intended to be definitive, the sort of studies done to get new drugs approved. About half the candidate treatments work as intended, and when they do, the results are likely to be positive. For a well-designed test such as this, statistical significance is a reasonable guide to whether the effect is real.
The problem is that the media only show a subset of the (exciting) solid circles, and typically don’t show the (boring) empty circles. So, what you see is
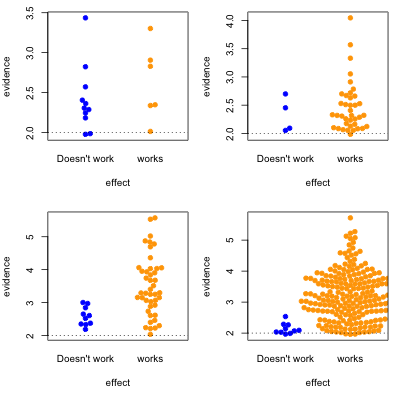
where the columns are 10% and 50% proportion of studies having a true effect, and the top and bottom rows are under-sized and well-design studies.
Knowing the threshold for evidence isn’t enough: the prior plausibility matters, and the ability of the study to demonstrate effects matters. Apparent effects seen in small or poorly-designed studies are less likely to be true.
 Every summer, the Department of Statistics offers scholarships to a number of students so they can work with staff on real-world projects. David, right, is working on the New Zealand General Social Survey 2014 with Professor Thomas Lumley and Associate Professor Brian McArdle of Statistics, and Senior Research Fellow Roy Lay-Yee and Professor Peter Davis from COMPASS, the Centre of Methods and Policy Application in the Social Sciences. David explains:
Every summer, the Department of Statistics offers scholarships to a number of students so they can work with staff on real-world projects. David, right, is working on the New Zealand General Social Survey 2014 with Professor Thomas Lumley and Associate Professor Brian McArdle of Statistics, and Senior Research Fellow Roy Lay-Yee and Professor Peter Davis from COMPASS, the Centre of Methods and Policy Application in the Social Sciences. David explains: