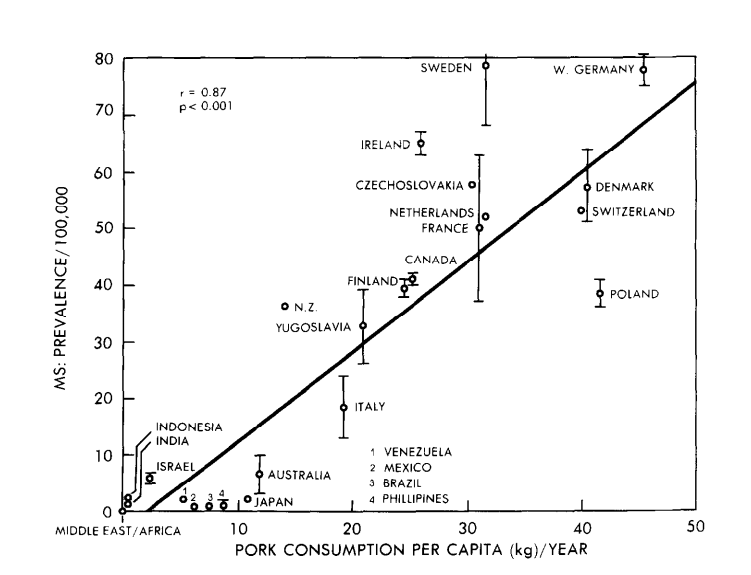
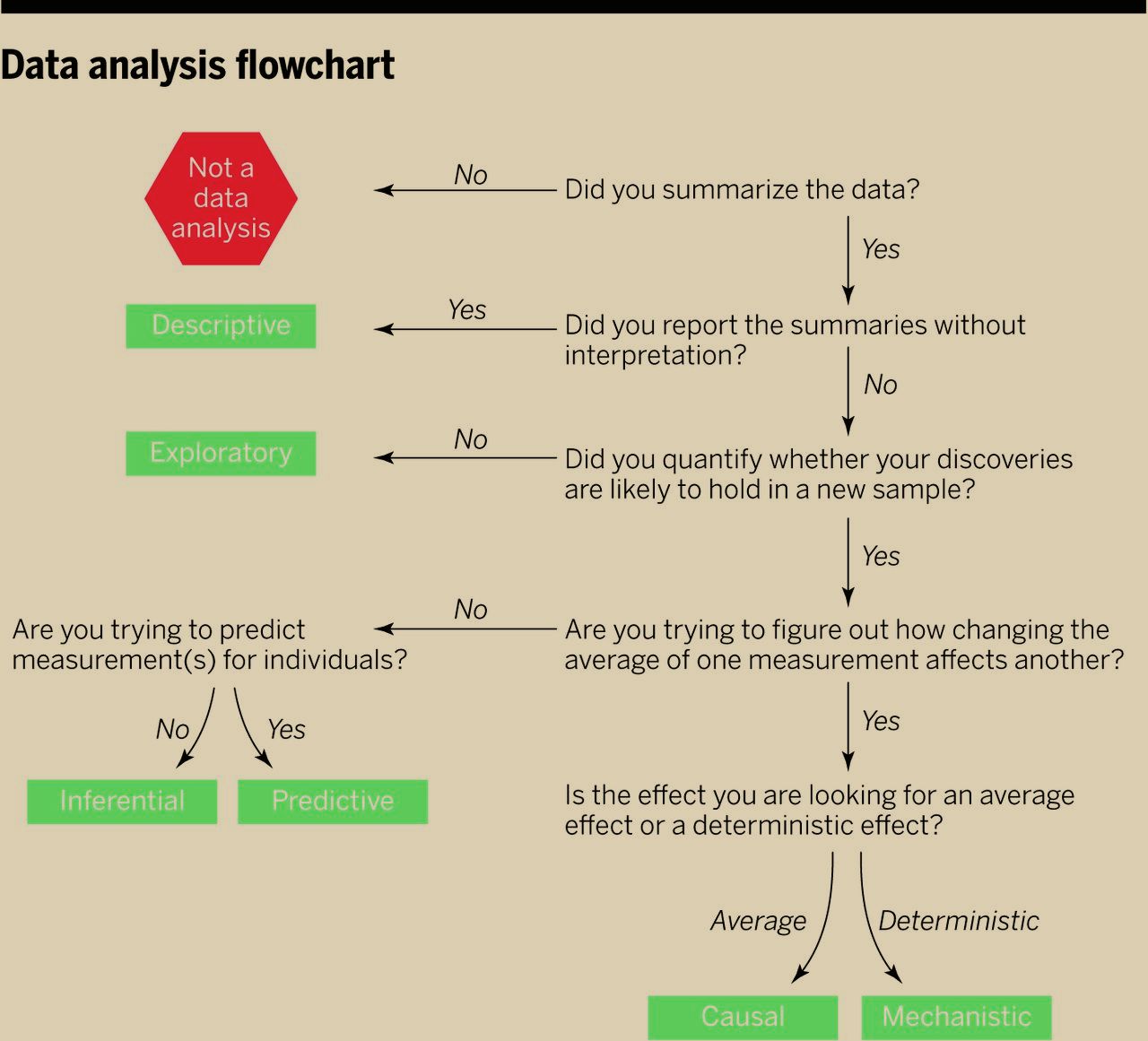
“Causal” is only the start
Jamie Morton has an interesting story in the Herald, reporting on research by Wellington firm Dot Loves Data.
They then investigated how well they all predicted the occurrence of assaults at “peak” times – between 10pm and 3am on weekends – and otherwise in “off-peak” times.
Unsurprisingly, a disproportionate number of assaults happened during peak times – but also within a very short distance of taverns.
The figures showed a much higher proportion of assault occurred in more deprived areas – and that, in off-peak times, socio-economic status proved a better predictor of assault than the nearness or number of bars.
Unsuprisingly, the police were unsurprised.
This isn’t just correlation: with good-quality location data and the difference between peak and other times, it’s not just a coincidence that the assaults happened near bars, nor is it just due to population density. The closeness of the bars and the assaults also argues against the simple reverse-causation explanation: that bars are just sited near their customers, and it’s the customers who are the problem.
So, it looks as if you can predict violent crimes from the location of bars (which would be more useful if you couldn’t just cut out the middleman and predict violent crimes from the locations of violent crimes). And if we moved the bars, the assaults would probably move with them: if we switched a florist’s shop and a bar, the assaults wouldn’t keep happening outside the florist’s.
What this doesn’t tell us directly is what would happen if we dramatically reduced the number of bars. It might be that we’d reduce violent crime. Or it might be that it would concentrate around the smaller number of bars. Or it might be that the relationship between bars and fights would weaken: people might get drunk and have fights in a wider range of convenient locations.
It’s hard to predict the impact of changes in regulation that are intended to have large effects on human behaviour — which is why it’s important to evaluate the impact of new rules, and ideally to have some automatic way of removing them if they didn’t do what they were supposed to. Like the ban on pseudoephedrine in cold medicine.