You see widely varying estimates for the probability of getting long Covid and for the recovery prognosis. Some of this is because people are picking numbers to recirculate that match their prejudices, but some of it is because these are hard questions to answer.
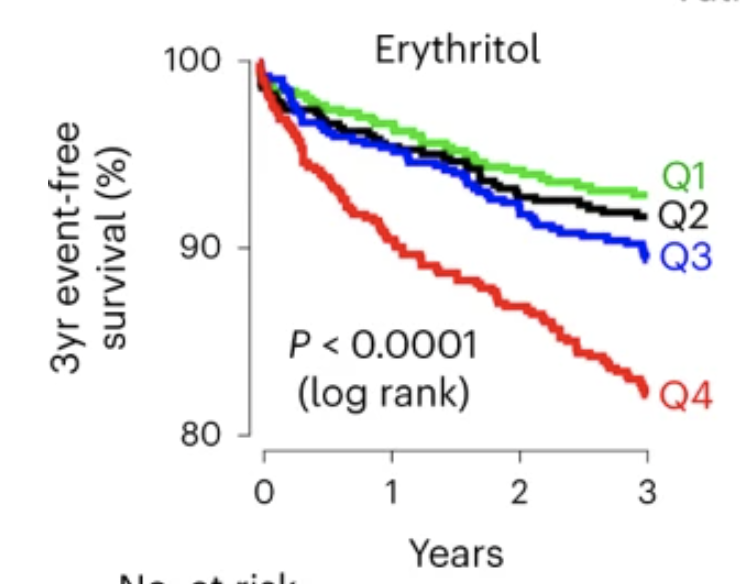
For example, the Hamilton Spectator (other Hamilton, not ours) reports a Canadian study following 106 people for a year. The headline was initially 75 per cent of COVID ‘long haulers’ free of symptoms in 12 months: McMaster study. It’s now 25 per cent of COVID patients become ‘long haulers’ after 12 months: Mac study. Both are misleading, though the second is better.
This study started out with 106 people, with an average age of 57. They had substantially more severe Covid than average:
Twenty-six patients recovered from COVID19 at home, 35 were admitted to the ICU, and 45 were hospitalized but not ICU-admitted
For comparison, in New Zealand the hospitalisation rate has been about 1% of reported cases, with about 0.03% of reported cases admitted to the ICU. It’s not a representative sample, and this matters for estimating overall prevalence. On top of that, only half the study participants have 12-month data. That means the proportion known to have become ‘long-haulers’ is only about 12%; the 25% is a guess that the people who didn’t continue with the study were similar.
A more general problem is that “long covid” isn’t an easily measurable thing. There are people who are still unwell in various ways a long time after they get Covid. There are multiple theories about what exactly is the mechanism, and it’s quite possible that more than one of these theories is true — we don’t even know that ‘long covid’ is just a single condition. Because we aren’t sure about the mechanism or mechanisms, there isn’t a test for long Covid the way there is for Covid. If you have symptoms plus a positive RAT or PCR test for the SARS-2-Cov virus you have Covid; that’s what ‘having Covid’ means. There isn’t a simple, objective definition like that for long Covid.
Because there isn’t a simple, objective test for long covid, different studies define it in different ways: usually as having had Covid plus some set of symptoms later in time. Different studies use different symptoms. The larger the study, the more generic the symptom measurements tend to be, and so you’d expect higher rates of people to report having those symptoms. If you simply ask about ‘fatigue’ you’ll pick up people with ordinary everyday <gestures-broadly-at-internet-and-world> as well as people with crushing post-Covid exhaustion, even though they’re very different.
There are also different time-frames in different studies: more people will have symptoms for three months than for twelve months just because twelve months is longer. Twelve-month follow-up also implies the study must have started earlier; a study that followed people for twelve months after initial illness won’t include anyone who had Omicron and might include a lot of unvaccinated people.
The different definitions and different populations matter. The majority of people in New Zealand have had Covid. There’s no way that 25% them have the sort of long Covid that someone like Jenene Crossan or Daniel Freeman did; it would be obvious in the basic functioning of society. Some people do have disabling long Covid; some people have milder versions; some have annoying post-Covid symptoms; some people seem to recover ok (though they might be at higher risk of other disease in the future). We don’t have good numbers on the size of these groups, or ways to predict who is who, or treatments, and it’s partly because it’s difficult and partly because the pandemic keeps changing.
It’s also partly because we haven’t put enough resources into it.
Recent comments on Thomas Lumley’s posts