Making it up in volume
This isn’t precisely statistics in the media, but it’s research about the sort of stories we discuss a lot. A new research paper in Nature looks at three estimates over time of the proportion of people vaccinated in the US. Two of these were based on large self-selected sets of respondents, the third was much smaller but had an attempt at random sampling.
What’s interesting about this is that we know the truth, pretty well. US States kept track of vaccinations and the CDC collated the data. There aren’t many examples where we have that sort of ground truth — the closest we come is elections, and even then we only get the truth for one point in time.
Here’s a graph from the research paper:
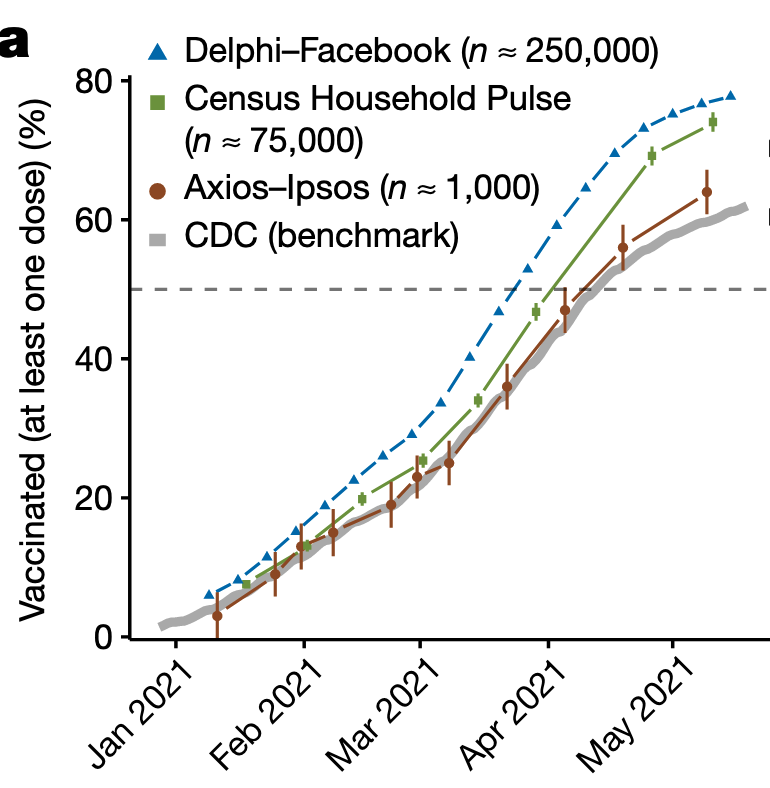
The two ‘big data’ estimates were much more precise than the smaller survey, but also much more biased: they were confidently wrong, where the small survey was pretty much right. For some reason (and it’s not hard to think of possibilities) people who were vaccinated were more likely to respond in the big unselected data sets.
This is a general ‘big data’ phenomenon: when you get more data it tends to be of lower quality. It’s very hard to overcome the data quality problem, so you will often get worse answers, but your estimation procedure will tell you they are much better. The ‘margin of error’ on the 75,000-person Census Household Pulse is much smaller than on the Axios-Ipsos survey, but the actual error is much larger. If you’ve seen lots of 1000-person surveys reported in the media and wondered why they aren’t bigger, this is the reason. It’s not that you can’t do a 10,000-person survey; it’s that it needs to have much higher data quality than a 1000-person survey to be worth doing.
Now, ‘big data’ isn’t useless. It can be possible, with detailed enough data on a large number of people, to get around the data quality problems. The polling company YouGov has had some success with large unselected samples and reweighting them to match the population. But that’s only possible where you have good data for the sample and the population — the Nature paper hypothesises that collecting political affiliation and rurality might have helped, but the ‘big data’ surveys didn’t.
I didn’t have anything to do with this research, but one of my research areas is combining big databases and small samples in medical research: in the small sample you can afford to get accurate data and then you can use the big database to get extra precision.
Thomas Lumley (@tslumley) is Professor of Biostatistics at the University of Auckland. His research interests include semiparametric models, survey sampling, statistical computing, foundations of statistics, and whatever methodological problems his medical collaborators come up with. He also blogs at Biased and Inefficient See all posts by Thomas Lumley »