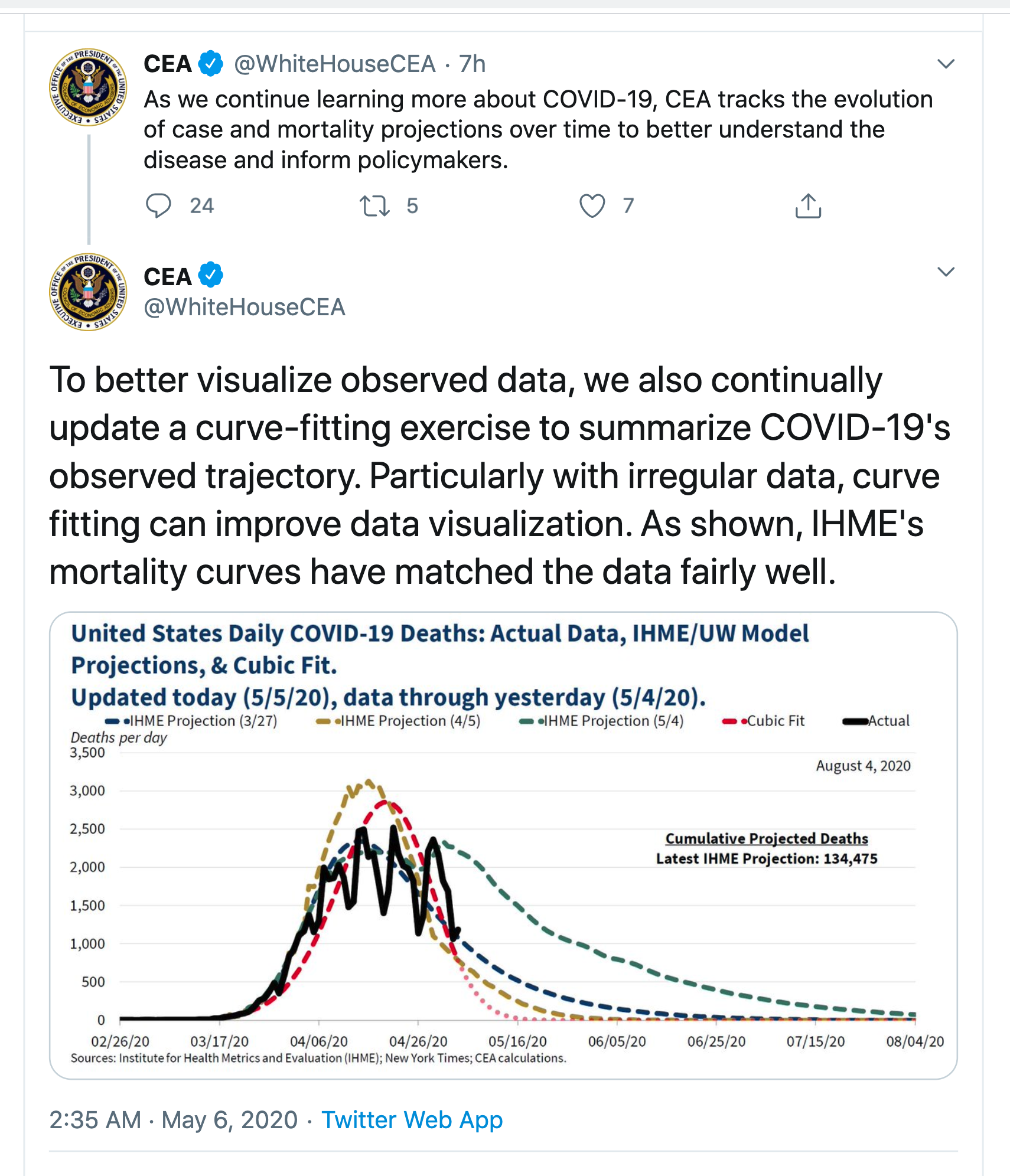
Austral….asia?
The Lancet published a paper recently claiming that chloroquine and hydroxychloroquine, with or without azithromycin and similar antibotics didn’t help COVID-19 but did cause heart problems, in 96000 people hospitalised for the disease across six continents.Since that’s what most people who would pay attention to a Lancet paper already believed, it was basically a confirmation. I argued that it made future randomised trials a bit unnecessary.
There is increasing concern about whether the paper accurately represented the source and quality of the data that went into the analysis. More precisely, sober and responsible people are even suggesting it might have been made up.
The Guardian has a headline: Covid-19 study on hydroxychloroquine use questioned by 120 researchers and medical professionals. Which, by now, is a big underestimate.
Probably the biggest concern is that idea that a software system released last year, could already be getting real-time clinical data from 671 hospitals in six continents, apparently with the rest of the healthcare informatics industry not noticing.
Also, there’s no data about the hospitals except which continent they are in, which is unusual for research of this type.
On top of that, some of the data are clearly wrong. I hadn’t read the paper carefully. I looked at it this morning in a bit more detail. One thing that jumped out was the claim that 609 of the hospitalised COVID cases were at five hospitals in Australia. This is using data up to April 14. On April 10, the Herald talked with Tony Blakely, who said there were 263 hospitalised cases in all of Australia. There’s no way these numbers match up.
It turns out that someone had noticed this already: the Australian data don’t match other data sources in other ways. In a new correction, the researchers said they had listed one hospital in the wrong continent. There were actually only 63 patients from Australia whose data was in the study, and one of the hospitals was in Asia:
“We have reviewed our Surgisphere database and discovered that a new hospital that joined the registry on April 1, and self-designated as belonging to the Australasia continental designation,”
They’d been mixed up because the hospital said it was in “Australasia”. Now, I’d think if you were setting up data access and non-disclosure contracts with hospitals, you’d want to know what country’s laws the hospitals operate under, but maybe machine learning can get around these issues.
A further interesting question is where this hospital could possibly be. Remember, it is supposed to have had 609-63=546 hospitalised, PCR-positive, COVID cases by April 14, and to be in Asia, and to have self-described as being in Australasia. We can rule out the Pacific islands that would be regarded as in Australasia — they don’t have anywhere near that many cases. Papua New Guinea has eight confirmed cases, counting up to right now. Timor-Leste has 24.
Could it be a hospital in Indonesia? Indonesia started testing very late, so 546 PCR-confirmed, hospitalised patients by April 14 is a fair chunk of the whole country. The special COVID hospital that’s now at the Asian Games’ athletes’ village near Jakarta has been in the news, and it’s got the right sort of patient numbers, and so there might be a couple of other Indonesian candidates. But it’s hard to see them self-describing as being in “Australasia”, or as having signed up to this new database system in the middle of a pandemic.