It’s warmer out there
Following a discussion on Twitter this morning, I thought I’d write again about increasing global temperatures, and also about the types of probability statements.
The Berkeley Earth Surface Temperature project is the most straightforward source for conclusions about warming in the recent past. The project was founded by Richard Muller, a physicist who was concerned about the treatment of the raw temperature measurements in some climate projections. At one point, there was a valid concern that the increasing average temperatures could be some sort of statistical artefact based on city growth (‘urban heat island’) or on the different spatial distribution and accuracy of recent and older monitors. This turned out not to be the case. Temperatures are increasing, systematically. The Berkeley Earth estimate agrees very well with the NASA, NOAA, and Hadley/CRU estimates for recent decades
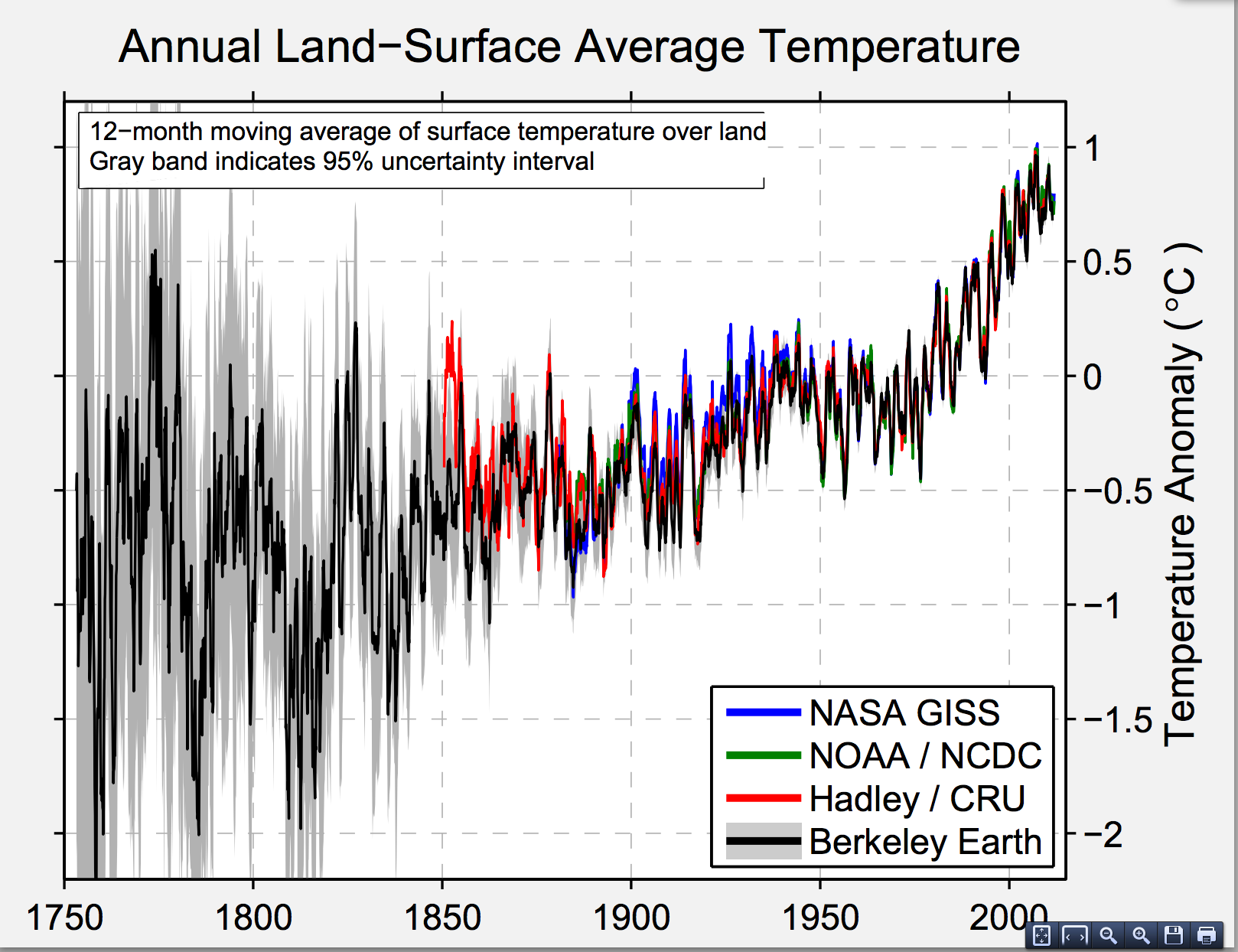
The grey band around the curve is also important. This is the random error. There basically isn’t any. To be precise, for recent years, the difference between current and average temperatures is 20 to 40 times the uncertainty — compare this to the 5σ used in particle physics.
What there is uncertainty about is the future (where prediction is hard), and the causal processes involved. That’s not to say it’s a complete free-for-all. The broad global trends fit very well to a simple model based on CO2 concentration plus the cooling effects of major volcanic eruptions, but the detail is hard to predict.
Berkeley Earth has a page comparing reconstructions of temperatures with actual data for many climate models. The models in the last major IPCC assessment report show a fairly wide band of prediction uncertainty — implying that future temperatures are more uncertain than current temperatures. The lines still all go up, but by varying amounts.
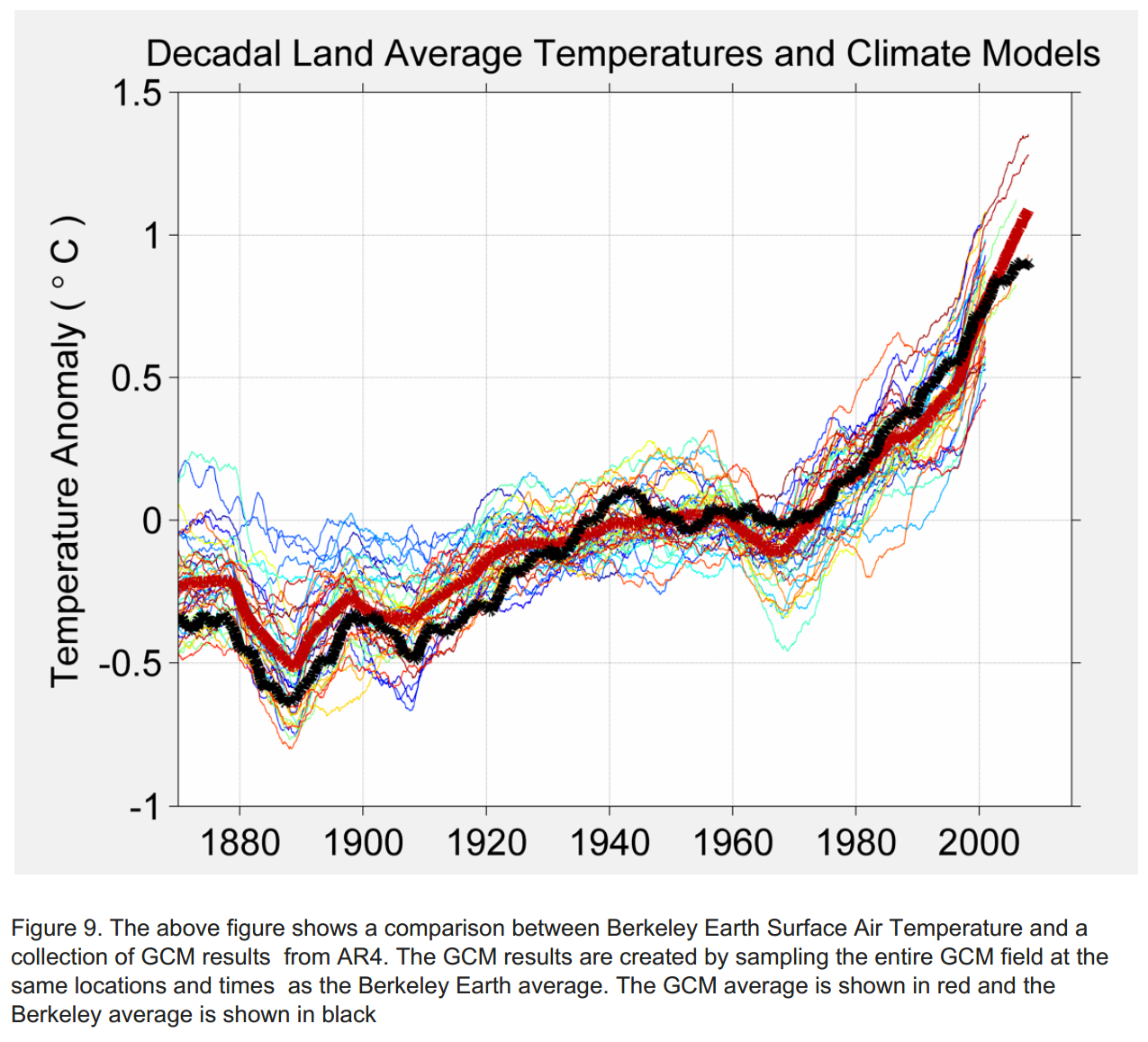
The same page has a detailed comparison of the regional accuracy of the models used in the new IPCC report. The overall trend is clear, but none of the models is uniformly accurate. That’s where the uncertainty comes from in the IPCC statements.
The earth has warmed, and as the oceans catch up there will be sea levels rises. That’s current data, without any forecasting. There’s basically no uncertainty there.
It’s extremely likely that the warming will continue, and very likely that it is predominantly due to human-driven emissions of greenhouses gases.
We don’t know accurately how much warming there will be, or exactly how it will be distributed. That’s not an argument against acting. The short-term and medium-term harm of climate changes increases faster than linearly with the temperature (4 degrees is much worse than 2 degrees, not twice as bad), which means the expected benefit of doing something to fix it is greater than if we had the same average prediction with zero uncertainty.
Thomas Lumley (@tslumley) is Professor of Biostatistics at the University of Auckland. His research interests include semiparametric models, survey sampling, statistical computing, foundations of statistics, and whatever methodological problems his medical collaborators come up with. He also blogs at Biased and Inefficient See all posts by Thomas Lumley »
I think it’s really interesting to use ‘statistics’ to quantify the strength of the evidence for global warming based on that time series. However it’s funny when people think that’s all there is to it, as though we don’t know anything about temperature, radiation, and carbon dioxide. Even if the data were completely flat there’d still be enough reason to consider future warming somewhat plausible.
10 years ago
Of course. On the other hand, the potential feedback loops are strong enough that I don’t think we could say muchmore than ‘plausible’ without detailed modelling.
10 years ago