Are girl hurricanes less scary?
There’s a new paper out in the journal PNAS claiming that hurricanes with female names cause three times as many deaths as those with male names (because people don’t give girl hurricanes the proper respect). Ed Yong does a good job of explaining why this is probably bogus, but no-one seems to have drawn any graphs, which I think make the situation a lot clearer.
Here’s the raw comparison: a boxplot of deaths from hurricanes that have made landfall in the US since 1950, by the gender of their name.
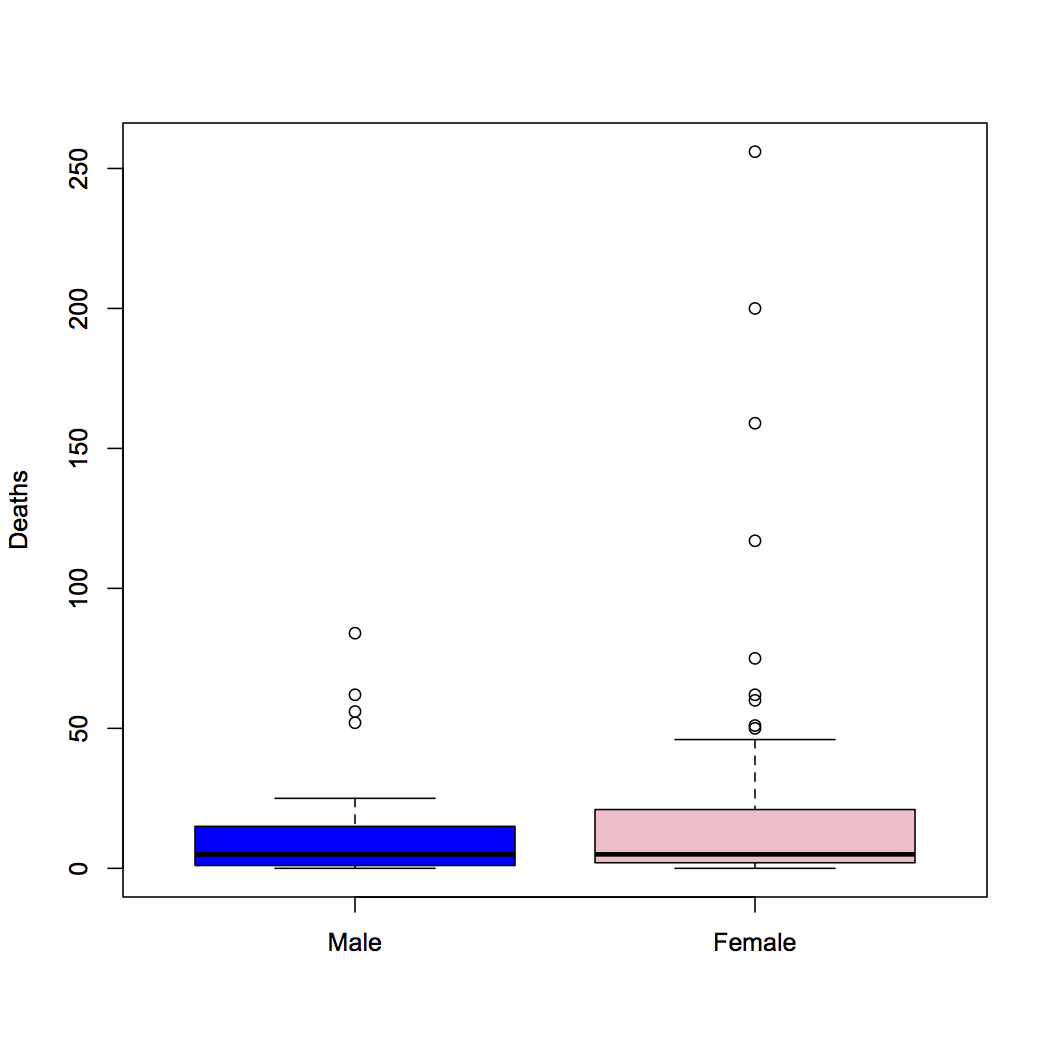
There have been more deaths from female-named hurricanes, but it’s obvious that the data are pretty skewed. What’s not obvious is that there have been about twice as many hurricanes with female names: the current practice of alternating genders started in 1979.
Unless we can be fairly sure there is no time trend, comparing hurricanes before 1979 to those after 1979 is going to be unhelpful, and in fact there is a time trend. The typical hurricane is getting more expensive, but less deadly.
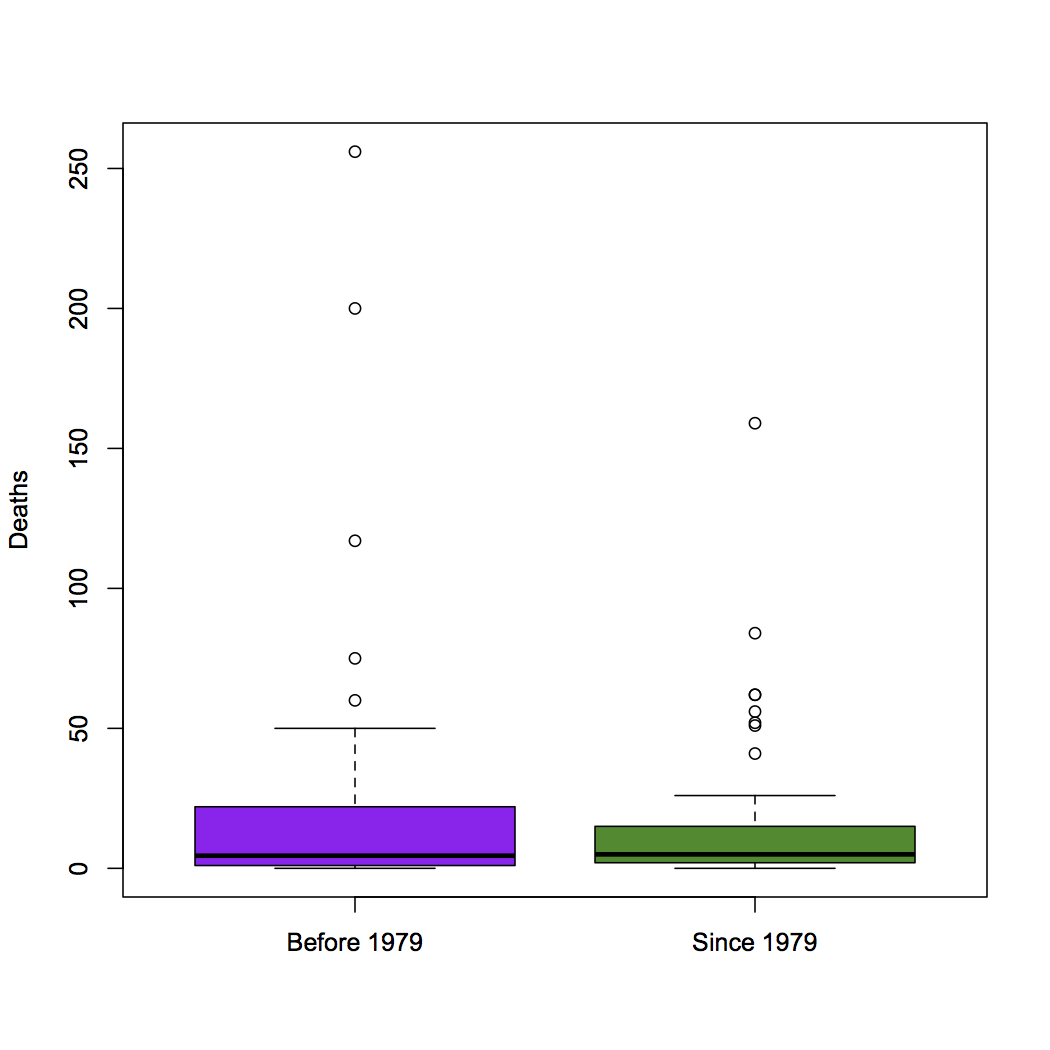
Hurricanes had male names in the early 1950s, female names from 1953 to 1979 (with the arguable exception of ‘Ione’ in 1955, which the researchers categorised as male), and then started alternating:
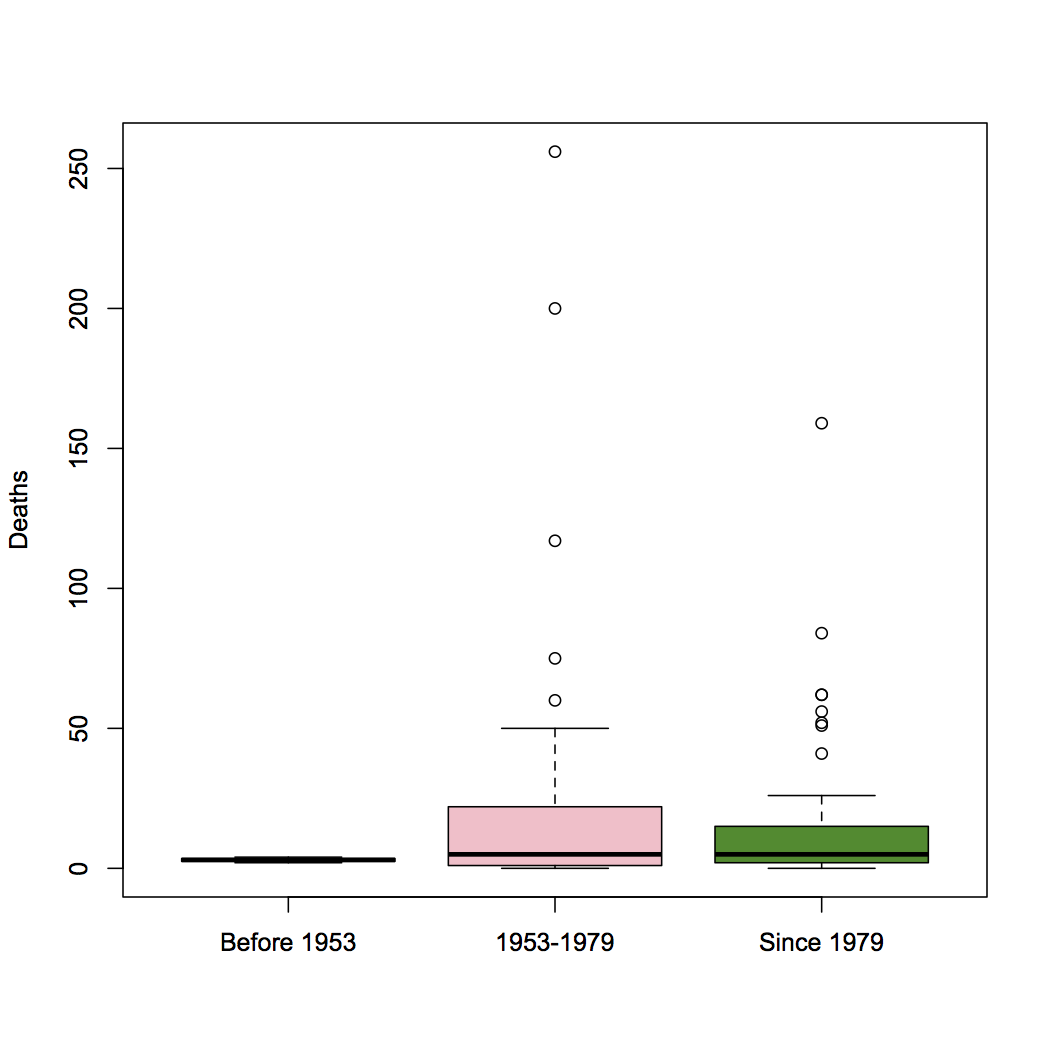
The only useful comparison is going to use data since 1979, where the difference is very unimpressive
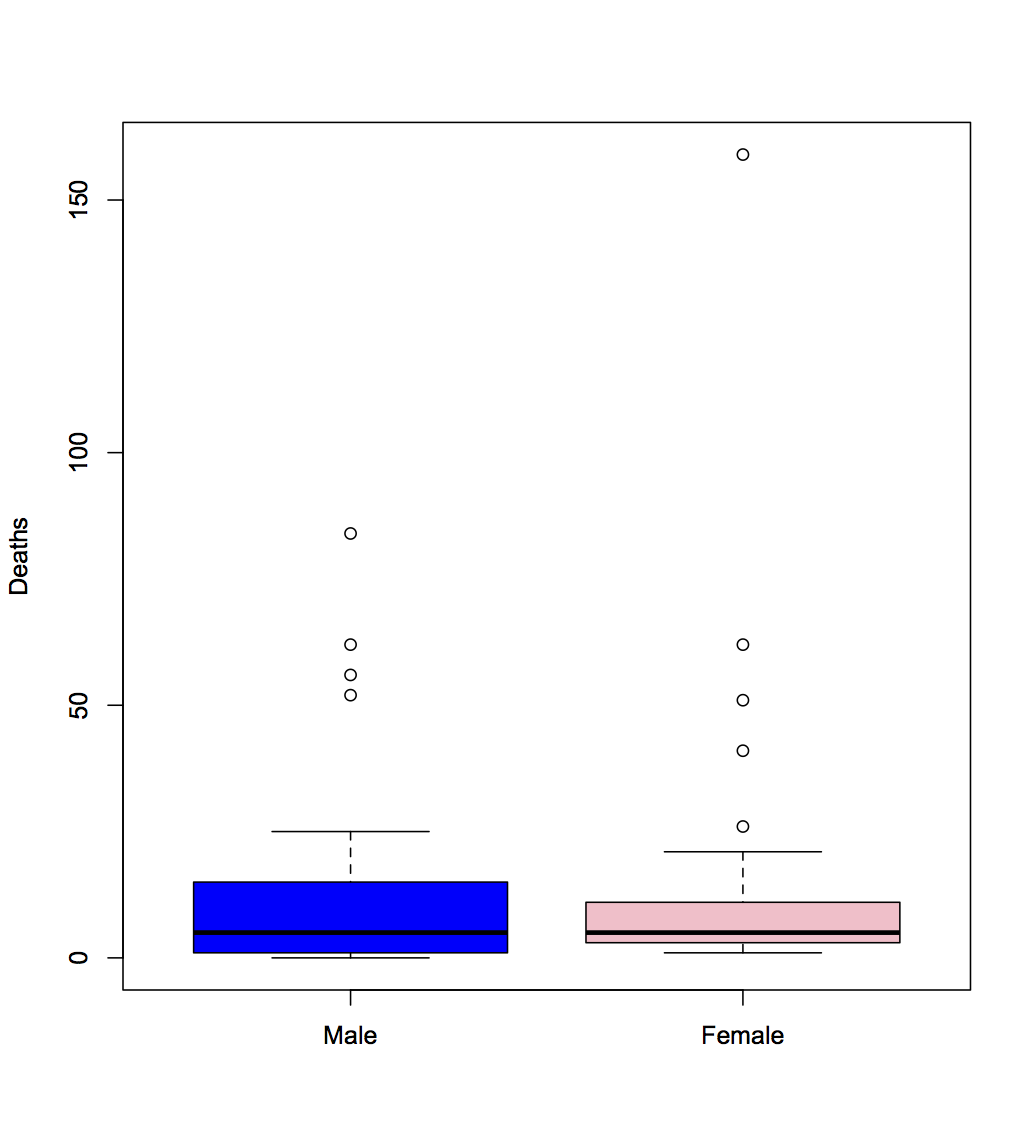
Since 1979, the mean number of deaths has been slightly higher with female names (17 vs 15.33) and the median has been the same (5). slightly lower (5 vs 6.5). Both differences are well within random error. There is no real suggestion of a difference in the data. This could be because there isn’t enough data, but in that case there isn’t enough data and there’s no reason to write the paper.
The researchers do provide some evidence that people taking part in psychological experiments give different answers about hurricanes with male or female names, which is interesting, but it’s a solution without a problem.
Thomas Lumley (@tslumley) is Professor of Biostatistics at the University of Auckland. His research interests include semiparametric models, survey sampling, statistical computing, foundations of statistics, and whatever methodological problems his medical collaborators come up with. He also blogs at Biased and Inefficient See all posts by Thomas Lumley »