Caricatures in language space
There’s an interesting (and open-access) paper in the journal PLoS One that I would have expected to attract more media attention both for its results and for its visualisations.
The researchers looked at words that distinguished people by age and gender (or, to be precise, what they had told Facebook were their age and gender). Here’s the female half of the graphic showing male/female distinguishing words (the full image, here, ‘contains language’)
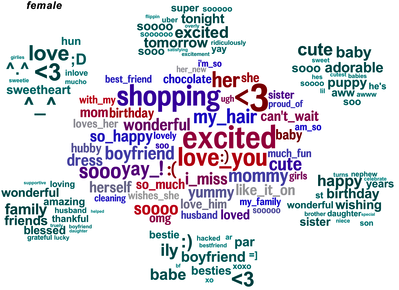
The clump in the middle are the words that are the most effective evidence that the writer is female. That doesn’t mean these words are especially frequent in women’s Facebook posts, just that they are much less frequent in men’s posts. The green clumps are the most-distinguishing topics, as identified statistically, with the words that define those topics.
Analyses like this are bound to come up with results that look like a caricature, since they are obtained in much the same way that a caricature is drawn, by finding and highlighting the most extreme and distinctive aspects.
Thomas Lumley (@tslumley) is Professor of Biostatistics at the University of Auckland. His research interests include semiparametric models, survey sampling, statistical computing, foundations of statistics, and whatever methodological problems his medical collaborators come up with. He also blogs at Biased and Inefficient See all posts by Thomas Lumley »
“Analyses like this are bound to come up with results that look like a caricature, since they are obtained in much the same way that a caricature is drawn, by finding and highlighting the most extreme and distinctive aspects.”
Nice analogy.
12 years ago