How recommendation systems work: beer
It’s nearly that time of the week, so here’s a post describing a simple beer recommendation system using 1.5 million ratings from BeerAdvocate.com and analysis in R
I don’t need a statistical model to tell me that someone who likes Fat Tire is probably going to like Dale’s Pale Ale more than Michelob Ultra. But what about picking between Dale’s Pale Ale and Sierra Nevada Pale Ale? Things get a little more complicated. For this reason (and because we don’t want to manually select between each beer pair), we’re going to write a distance function that will quantify similarity.
For our similarity metric we’re going to use a weighted average of the correlation of each metric. In other words, for each two-beer-pair we calculate the corelation of
review_overall,review_aroma,review_palate, andreview_tasteseperately. Then we take a weighted average each result to consolidate them into one number.
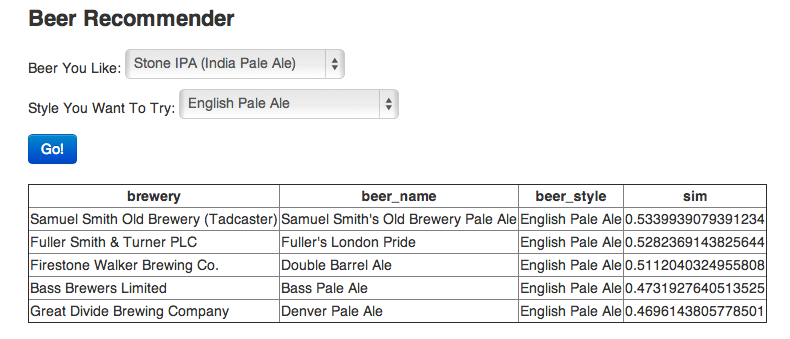
The resulting tool lets you put in a specific beer you like and then ask for recommendations in a category, eg,
Thomas Lumley (@tslumley) is Professor of Biostatistics at the University of Auckland. His research interests include semiparametric models, survey sampling, statistical computing, foundations of statistics, and whatever methodological problems his medical collaborators come up with. He also blogs at Biased and Inefficient See all posts by Thomas Lumley »