March 11, 2013
Stat of the Week Competition Discussion: March 9 – 15 2013
If you’d like to comment on or debate any of this week’s Stat of the Week nominations, please do so below!
If you’d like to comment on or debate any of this week’s Stat of the Week nominations, please do so below!
From NIWA, soil moisture across the country (via @nzben on Twitter), compared to the same time last year and to the average for this date.
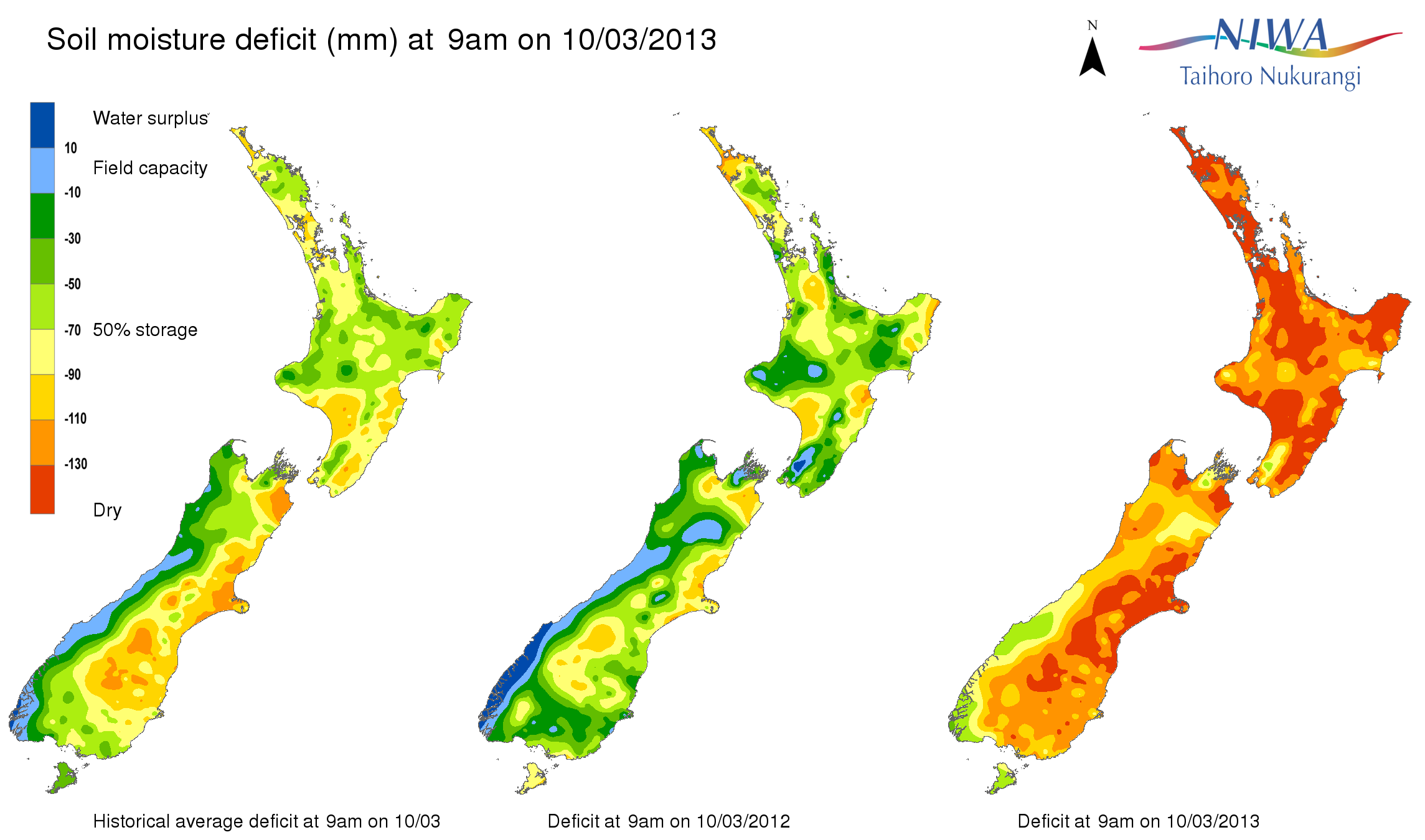
Update: If I had to be picky about something: that light blue colour. It doesn’t really fit in the sequence.
Update: Stuff also has a NIWA map, and theirs looks worse, but it’s based on rainfall over just the past three weeks (and, strangely, labelled “Drought levels over the past six days”)
Last night, 3News had a scare story about positive drug tests at work. The web headline is “Report: More NZers working on drugs”, but that’s not what they had information on:
New figures reveal more New Zealanders were caught with drugs in their system at work last year.
…new figures from the New Zealand Drug Detection Agency reveal 4300 people tested positive for drugs at work last year.
but
The New Zealand Drug Detection Agency says employers are doing a better job of self-regulating. The agency performed almost 70,000 tests last year, 30 percent more than in 2011.
If 30% more were tested, you’d expect more to be positive. The story doesn’t say how many tested positive the previous year, but with the help of the Google, I found last year’s press release, which says
8% of men tested “non-negative” compared with 6% of women tested in 2011.
Now, 8% of 70000 is 5600, and even 6% of 70000 is 4200. Given that the majority of the tests are in men, it looks like the proportion testing positive went down this year.
The worst part of the story statistically is when they report changes in proportions of which drug was found as if this was meaningful. For example,
When it comes to industries, oil and gas had an 18 percent drop in positive tests for methamphetamine, but showed a marked increase in the use of opiates.
That’s an increase in the use of opiates as a proportion of those testing positive. Since proportions have to add up to 100%, a decrease in the proportion positive tests that are for methamphetamine has to come with an increase in some other set of drugs — just as a matter of arithmetic.
Stuff‘s story from January just as bad, with the lead
Employers are becoming more aware of the dangers of drugs and alcohol in the workplace as well as the benefits of testing for them.
and quoting an employer as saying
“And, we have no fear of an employee turning up to work and operating in an unsafe way, putting themselves and others at risk.”
as if occasional drug tests were the answer to all occupational health and safety problems.
The other interesting thing about the Stuff story is that it’s about a different organisation: Drug Testing Services, not NZ DDA — there’s more than one of them out there! You might easily have thought from the 3News story that the figures they quoted referred to all workplace drug tests in NZ, rather than just those sold by one company.
Given the claims being made, the evidence for either financial or safety benefits is amazingly weak. No-one in these stories even claims that introducing testing has actually reduced on-the-job accidents in their company, for example, let alone presents any data.
If you look on PubMed, the database of published medical research, there are lots of papers on new testing methods and reproducibility of test results, and a few that show people who have accidents are more likely than others to test positive. There’s very little even of before-after comparisons: a Cochrane review on this topic found three before-after comparisons. Two of the three found a small decrease in accident rates immediately after introducing testing; the third did not. A different two of the three found that the long-term decreasing trend in injuries got faster after introducing testing; again, the third did not. The review concluded that there was insufficient evidence to recommend for or against testing.
There’s better evidence for mandatory alcohol testing of truck drivers, but since those tests measure current blood alcohol concentrations, not past use, it doesn’t tell us much about other types of drug testing.
I’m sure that many of our readers are familiar with the latest internet trend, the Harlem Shake. Recently, a statistical version appeared that demonstrates some properties of popular Markov Chain Monte Carlo (MCMC) algorithms. MCMC methods are computer algorithms that are used to draw random samples from probability distributions that might have complicated shapes and live in multi-dimensional spaces.
MCMC was originally invented by physicists (justifying my existence in a statistics department) and is particularly useful for doing a kind of statistics called “Bayesian Inference” where probabilities are used to describe degrees of certainty and uncertainty, rather than frequencies of occurrence (insert plug for STATS331, taught by me, here).
Anyway, onto the HarleMCMC shake. It begins by showing the Metropolis-Hastings method, which is very useful and quite simple to do, but can (in some problems) be very slow, which corresponds to the subdued mood at the beginning of a Harlem Shake. As the song switches into the intense phase, the method is replaced by the “Hamiltonian MCMC” method which can be much more efficient. The motion is much more intense and efficient after that!
Here is the original video by PhD students Tamara Broderick (UC Berkeley) and David Duvenaud (U Cambridge):
http://www.youtube.com/watch?v=Vv3f0QNWvWQ
Naturally, this inspired those of us who work on our own MCMC algorithms to create response videos showing that Hamiltonian MCMC isn’t the only efficient method! Within one day, NYU PhD student Daniel Foreman-Mackey had his own version that uses his emcee sampler. I also had a go using my DNest sampler, but it has not been set to music yet.
So, next time you read or hear about a great new MCMC method, you should ask the authors how well it performs on the “Harlem Shake Distribution”. Oh and thanks to Auckland PhD student Jared Tobin for linking me to the original video!
The Herald, under the arguably-overstated headline Eating processed meats could cut your life short, have the reasonable lead
A diet packed with sausages, ham, bacon and other processed meats appears to be linked to an increased risk of dying young, a study of half a million people across Europe suggests.
The main problem with the summaries of risk that reported in the story is that they are for the people who eat the highest amount of processed meat. It’s notable that nowhere in the Herald story do they tell you how high this consumption level was, either as a fraction of the participants or as a weight or number of servings. (3News did better)
It’s probably true that you would have lower risk if you ate less processed meat than this highest-consumption group, but you probably already do — they were the top half a percent of the 450000 participants, and they averaged more than 160g per day, or 1.1kg per week.
There are also problems with how the statistics get translated into deaths. The study estimated hazard ratios, which compare the rates of death for high and low processed meat consumption, and then try to turn these into proportions. The Herald quotes a study researcher as saying
“Overall, we estimate that 3 per cent of premature deaths each year could be prevented if people ate less than 20 grams of processed meat per day.”
This should get the response “define ‘premature'”, but it’s actually more carefully phrased than in the research paper, which says
We estimated that 3.3% (95% CI 1.5% to 5.0%) of deaths could be prevented if all participants had a processed meat consumption of less than 20 g/day.
suggesting that 3.3% of vegetarians would be immortal.
Turning hazard ratios into information about life expectancy or premature death is tricky. David Spiegelhalter’s microlives are useful here. The study estimates a hazard ratio of 1.18 for 50g extra per day of processed meat. If that really is due to the meat, not to other differences in health risk, and if it really is approximately constant across all types of processed meat, it corresponds to about 2 microlives per 50g — about an hour of life per serving, or about the same as four cigarettes.
There are reasons to be a bit skeptical about the magnitude of the results: the study didn’t find any evidence of higher risk in people who eat a lot of red meat, contradicting previous studies. Also, the analysis used statistical techniques to correct for measurement error in meat consumption, but not in any of the other risk factors they analysed. If people with high processed meat consumption are also at higher risk in other ways (which they are), this analysis will tend to shift the apparent risk towards processed meat.
Still, I shouldn’t think anyone is really surprised that bacon’s not a health food.
There’s a fuss at the moment in Britain over the recreational genotyping companies that purport to tell you where your ancestors came from. One of the stories that provoked this, was the claim that over 1 million Brits are descended from Roman soldiers. For example, in the Telegraph, under the headline “One million Brits ‘descended from Romans'”
The Romans departed abruptly in the early fifth century, leaving behind relics of their rule including Hadrian’s Wall along with a host of towns, roads and encampments.
But perhaps the most enduring sign of their legacy is in our genes, experts claim, with an estimated million British men descending from the invading forces.
The first sign that something is wrong is that ‘one million Brits’ turns into ‘a million British men’. What about the women? The reason for the `one million’ estimate is the same as the reason it’s just men — the ‘experts’ are looking only at male-line descent, via the Y chromosome. In fact, the number of British men descended from Roman soldiers is probably more like 25 million. That is, there’s a general principle that anyone in the distant past is either a direct ancestor of no-one in the present, or of almost everyone in the present.
If you go back 100 generations to the time of Roman occupation of Britain, you would have 1267650600228229401496703205376 ancestors. That’s roughly a bazillion times the number of people alive then, so there is a lot of overlap. If you look just at pure male-line ancestors, from whom you inherited a Y chromosome, you either have none (if you don’t have a Y chromosome) or one. It’s clear why the ancestry-mongers want to simplify their sales pitch by focusing on the Y chromosome (and on mitochondrial DNA, which is inherited through the female line), but it’s not clear why anyone should listen to them.
Even if you live in Britain and your Y chromosome came from someone in Roman legions, it didn’t necessarily come via the British occupation. After all, lots of men have migrated to Britain since then: the Vikings and the Normans back in History, and more recently from all over the world. Some of them would have had Roman-looking Y chromosomes too. And even the idea of a ‘Roman’ Y-chromosome is a bit dodgy. Broadly speaking, a group of Y chromosomes tends to get attributed to the region in the world where it is seen most today (unless that’s, say, the US). There’s no guarantee that this is where the Y-chromosome group was common 1000 years ago.
There is some potential for using whole-genome data to say something more meaningful about relatively recent ancestry, but to be useful even that needs to come with uncertainty estimates, which will often be huge.
Sense about Science have put out a good information sheet, but the basic message is that at the moment anything interesting someone tells you about your distant ancestors based on genetic information, they could tell you equally well without bothering to do any genotyping.
A presentation from Jonathan Corum, who works at the New York Times.
Read it for the content, and read it to see how a speech with slides can be turned into an effective webpage.
This is based on his keynote talk at the Tapestry conference, which was held just before the Computer-Assisted Reporting conference I mentioned last weekend.
(via)
If you’ve ever viewed Twitter as a gauge of public opinion, a weathervane marking the mood of the masses, you are very much mistaken.
That is the rather surprising finding of a new US study, which suggests the microblog zeitgeist differs markedly from mainstream public opinion.
Apart from being completely unsurprising, this is a useful thing to have data on. The Pew Charitable Trusts, who do a lot of surveys, compared actual opinion polls to tweet summaries for some major political and social issues in the US, and found they didn’t agree.
Along the same lines, it was reported last month that Google’s Flu Trends overestimated the number of flu cases this year (after having initially underestimated the H1N1 pandemic), probably because the high level of publicity for the flu vaccine this year made people more aware.
These data summaries can be very useful, because they are much less expensive and give much more detail in space and time than traditional data collection, but they are also sensitive to changes in online behaviour. Getting anything accurate out of them requires calibration to ‘ground truth’, as a previous generation of Big Data systems called it.
This year the predictions have been slightly changed with the help of a student, Joshua Dale. The home ground advantage now is different when both teams are from the same country to when the teams are from different countries. The basic method is described on my Department home page.
Here are the team ratings prior to Round 4, along with the ratings at the start of the season.
| Current Rating | Rating at Season Start | Difference | |
|---|---|---|---|
| Chiefs | 9.58 | 6.98 | 2.60 |
| Crusaders | 6.90 | 9.03 | -2.10 |
| Sharks | 4.76 | 4.57 | 0.20 |
| Stormers | 2.70 | 3.34 | -0.60 |
| Bulls | 2.42 | 2.55 | -0.10 |
| Hurricanes | 2.07 | 4.40 | -2.30 |
| Brumbies | 1.02 | -1.06 | 2.10 |
| Blues | 1.02 | -3.02 | 4.00 |
| Reds | -0.30 | 0.46 | -0.80 |
| Highlanders | -3.90 | -3.41 | -0.50 |
| Waratahs | -4.62 | -4.10 | -0.50 |
| Cheetahs | -6.32 | -4.16 | -2.20 |
| Kings | -9.37 | -10.00 | 0.60 |
| Force | -10.16 | -9.73 | -0.40 |
| Rebels | -10.60 | -10.64 | 0.00 |
So far there have been 15 matches played, 13 of which were correctly predicted, a success rate of 86.7%.
Here are the predictions for last week’s games.
| Game | Date | Score | Prediction | Correct | |
|---|---|---|---|---|---|
| 1 | Blues vs. Crusaders | Mar 01 | 34 – 15 | -7.60 | FALSE |
| 2 | Waratahs vs. Rebels | Mar 01 | 31 – 26 | 9.10 | TRUE |
| 3 | Reds vs. Hurricanes | Mar 01 | 18 – 12 | 0.80 | TRUE |
| 4 | Chiefs vs. Cheetahs | Mar 02 | 45 – 3 | 15.70 | TRUE |
| 5 | Bulls vs. Force | Mar 02 | 36 – 26 | 17.80 | TRUE |
| 6 | Sharks vs. Stormers | Mar 02 | 12 – 6 | 4.30 | TRUE |
Here are the predictions for Round 4. The prediction is my estimated expected points difference with a positive margin being a win to the home team, and a negative margin a win to the away team.
| Game | Date | Winner | Prediction | |
|---|---|---|---|---|
| 1 | Hurricanes vs. Crusaders | Mar 08 | Crusaders | -2.30 |
| 2 | Rebels vs. Reds | Mar 08 | Reds | -7.80 |
| 3 | Highlanders vs. Cheetahs | Mar 09 | Highlanders | 6.40 |
| 4 | Brumbies vs. Waratahs | Mar 09 | Brumbies | 8.10 |
| 5 | Stormers vs. Chiefs | Mar 09 | Chiefs | -2.90 |
| 6 | Kings vs. Sharks | Mar 09 | Sharks | -11.60 |
| 7 | Blues vs. Bulls | Mar 10 | Blues | 2.60 |