What’s the actual margin of error?
The official maximum margin of error for an election poll with a simple random sample of 1000 people is 3.099%. Real life is more complicated.
In reality, not everyone is willing to talk to the nice researchers, so they either have to keep going until they get a representative-looking number of people in each group they are interested in, or take what they can get and reweight the data — if young people are under-represented, give each one more weight. Also, they can only get a simple random sample of telephones, so there are more complications in handling varying household sizes. And even once they have 1000 people, some of them will say “Dunno” or “The Conservatives? That’s the one with that nice Mr Key, isn’t it?”
After all this has shaken out it’s amazing the polls do as well as they do, and it would be unrealistic to hope that the pure mathematical elegance of the maximum margin of error held up exactly. Survey statisticians use the term “design effect” to describe how inefficient a sampling method is compared to ideal simple random sampling. If you have a design effect of 2, your sample of 1000 people is as good as an ideal simple random sample of 500 people.
We’d like to know the design effect for individual election polls, but it’s hard. There isn’t any mathematical formula for design effects under quota sampling, and while there is a mathematical estimate for design effects after reweighting it isn’t actually all that accurate. What we can do, thanks to Peter Green’s averaging code, is estimate the average design effect across multiple polls, by seeing how much the poll results really vary around the smooth trend. [Update: this is Wikipedia’s graph, but I used Peter’s code]
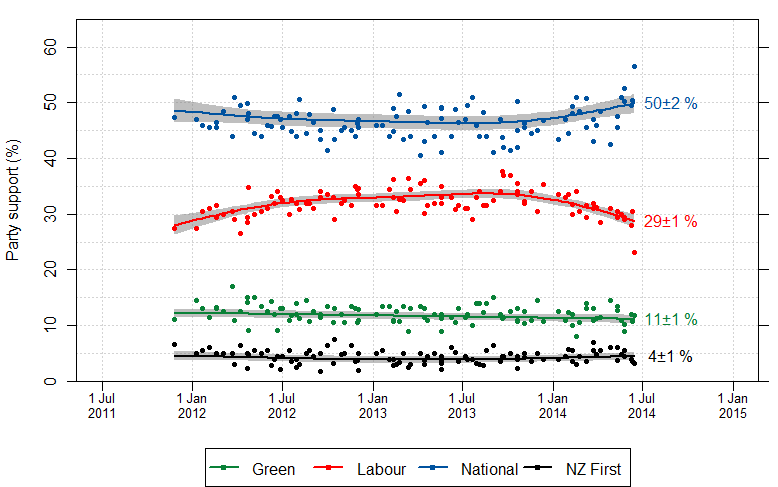
I did this for National because it’s easiest, and because their margin of error should be close to the maximum margin of error (since their vote is fairly close to 50%). The standard deviation of the residuals from the smooth trend curve is 2.1%, compared to 1.6% for a simple random sample of 1000 people. That would be a design effect of (2.1/1.6)2, or 1.8. Based on the Fairfax/Ipsos numbers, about half of that could be due to dropping the undecided voters.
In principle, I could have overestimated the design effect this way because sharp changes in party preference would look like unusually large random errors. That’s not a big issue here: if you re-estimate using a standard deviation estimator that’s resistant to big errors (the median absolute deviation) you get a slightly larger design effect estimate. There may be sharp changes, but there aren’t all that many of them, so they don’t have a big impact.
If the perfect mathematical maximum-margin-of-error is about 3.1%, the added real-world variability turns that into about 4.2%, which isn’t that bad. This doesn’t take bias into account — if something strange is happening with undecided voters, the impact could be a lot bigger than sampling error.
Thomas Lumley (@tslumley) is Professor of Biostatistics at the University of Auckland. His research interests include semiparametric models, survey sampling, statistical computing, foundations of statistics, and whatever methodological problems his medical collaborators come up with. He also blogs at Biased and Inefficient See all posts by Thomas Lumley »
Cool and interesting. Ta.
10 years ago
+1
That’s neat.
10 years ago
++1 (c programmer)
10 years ago
You fail to say if these margins are plus or minus. Can you please clarify as there is a huge difference between 4 (plus or minus 2) and plus or minus 4 (8) which a what I suspect it is.
10 years ago
+/-4, just as the standard one is +/-3
10 years ago
I would have thought bias was a more urgent problem than imprecision when some people refuse to respond. How is this problem solved?
10 years ago
To some extent the nonresponse is solved by reweighting. If voting preference is related to something like age, sex, ethnicity, or city vs regions, it’s possible to give different weights to people in the sample to match the sex, age, ethnicity, location distribution of the whole population, which we know from the Census. That sort of adjustment for surveys is one reason a Census is important.
This adjustment isn’t perfect, because non-responders are different even from other similar people, but it does help, and it’s a major reason that polls aren’t hopelessly biased.
In principle you could use election data to fix the remaining bias. The problem is there aren’t enough elections for that — just one every three years. It seems to work better in the US.
10 years ago